
AI & Ethics
Bias
미국 Northpointe社의 재범가능성(recidivism)을 예측하는 COMPAS는 아래와 같이 인종, 성별에 관해서 편향된 추측을 하는 경향과 법률적 근거가 모호해 폐기된 전례가 있다.

개인적인 생각으로 COMPAS는 법적 설득력의 부족과 잘못된 모델 설계의 문제로 인해 발생된 Bias 이슈라고 생각된다.
특정 성별, 인종, 종교에 편향되어 데이터를 분석했다면 해당 모델의 데이터 분석 방법론이 잘못된 것이지 개발자들의 신념에 따른 프로파간다가 아니기 때문이다. 왜냐하면 Imbalanced class distribution을 잘못 처리했고 이를 모델이 그대로 학습했다면 모델의 신뢰성은 보장할 수 없을 뿐더러, 모델의 추정 또한 정확하지 않기 때문이다.
중요한 것은 COMPAS의 개발 과정과 사용 데이터는 영업 비밀(trade secret)이다. 관련 기사 즉, 개발자가 인종차별적인 혹은 젠더 관련 신념에 의해서 Biased model을 개발한 것인지 혹은 단순 통계적 실수인지 모른다는 것이다.
또한 링크에 걸어둔 변호사님의 언급과 같이 적법절차원칙위반이라고 한다. 영업 비밀을 통해 채택된 증거는 피고인의 방어권이 발동될 여지가 없고 재판부 또한 판결의 근거로 사용할 수 없기 때문이다.
미국 NSTC(국가과학기술위원회)의 보고서 ‘Preparing For The Future Of Artificial Intelligence’는 ‘Fairness’에 관하여 한 챕터를 할애할만큼 Blackbox 형태의 학습 방법은 대중에게 알 권리를 보장하지 못한다. 따라서 이러한 Blackbox 형태로 인해 발생하는 인종, 성적 차별적 형태가 일어나지 않았음을 보증하는 것이 어렵고, 보증하기 위해 노력할 사안임은 분명하다.
Bias 관련 연구
Big data에서 Bias가 어떻게 발생하는지 연구되는 법학적 논문도 있다고 한다. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2477899 논문의 abstact는 문제의 근원을 알기 어렵기 때문에 정확한 solution을 찾는 것이 어렵다는 내용이다.
- 알고리즘은 데이터에 기반할 수 밖에 없다. 가령, 데이터가 편향됐다면 출력도 편향될 것이다.
- 이전 판사들의 판결 결과들이 편향됐다면, 알고리즘도 편향된 판결 결과를 내놓을 것이다. 즉, 사회적 편향성이 알고리즘에도 반영이 될 것이다.
- 사회적 데이터들에 소수자, 약자들에게 불리한 패턴이 존재할 수 있다. 하지만 이에 대한 정확한 데이터의 근원을 아는 것은 어렵다. (?)
- 개발사들이 bias한 모델 개발을 의도하진 않았지만 bias한 모델이 개발될 여지가 있다.
Define target variable and class labels
Target variable과 Class label을 정의할 때, 여기서부터 bias가 발생할 수 있다고 논문에서는 말한다. 가령, good employee를 정의해보자.
- 근속년수
- 하루 근무 시간
- 생산성
- 다른 근무자와의 관계
이러한 variable과 class의 조건을 정의할 때 bias가 발생할 수 있다는 것이다. 생산성을 어떻게 정의할 것인지, 하루 근무 시간을 어떻게 정의할 것인지에는 극히 주관적인 요소들이 포함될 수 있기 때문이다.
Labeling
LinkedIn Talent Match에서 Employee에 대한 평가는 Employer가 한다. Employer들이 implicityly biased할 수 있다. 이러한 평가 데이터가 학습 데이터에 반영될 수 있다. (?)
Collection
데이터 수집 자체에서 bias가 반영될 수 있다는 주장이다.
- Unerrepresentation
- 데이터가 취약계층을 대변하지 못하는 경우들이 있다.
- 가령, 보스턴 시에서는 시민들이 도로 파손 상태를 사진으로 찍어서 보고하여 수리를 하는데, 취약계층이 밀집한 지역에서는 스마트폰 보급이 안되서 이러한 보고가 제대로 이루어지지 않았다.
- Overrepresentation
- 데이터가 취약계층을 과다하게 반영
- 취약계층인 고용인의 활동이 고용자에게는 유독 주목받는 경우가 있을 수 있어서 객관적인 평가가 안될 수 있다.
Feature selection
Feature 자체에 bias가 반영돼있다는 주장이다. 이를 극복하기 위한 대표적인 예시가 블라인드 채용이다. redlining: general criteria를 보는 것. 개인의 평가보다 주변 환경에 대한 평가.
Proxies
- Unintentional discrimination
- 의도하지 않았지만 모델이 스스로 bias한 패턴을 찾아내는 경우
- Intentional discrimination
- 설계자가 의도해 bias를 알고리즘에 투입
Bias metrics
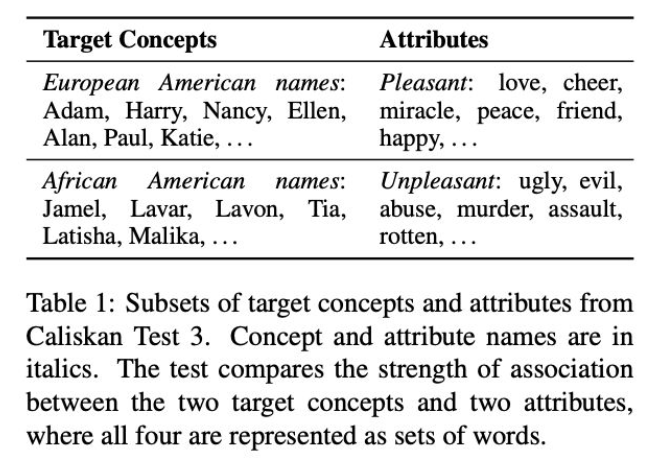 Source: May, et al. NAACL 2019
Source: May, et al. NAACL 2019
- 설계자가 의도해 bias를 알고리즘에 투입
NLP model에서 European American names는 긍정적인 단어와 context상 더 적절하고, African American names는 부정적인 단어와 context가 더 적절하게 학습되는 것이 알려져 있다고 한다.
 위 도식과 마찬가지로 sentence to sentence로 긍/부정 평가를 했을 때도 bias를 가지고 있다는 것이 해당 논문의 주장이다.
위 도식과 마찬가지로 sentence to sentence로 긍/부정 평가를 했을 때도 bias를 가지고 있다는 것이 해당 논문의 주장이다.
Bias 결론
민감한 주제이기 때문에 다른 포스팅보다 더 신경써서 다뤘다.
COMPAS는 AI와 Bias 사례를 소개할 때 설명하기 가장 적절한 예시이다. Bias data를 학습해 prediction 결과가 좋지 않았고, Blackbox 형태의 모델은 법률 증거로 채택될 설득력도 없으며, 피고인의 방어권을 보장할 수 없기 때문이다.
하지만 Bias된 결과에 대해서 집착하지 않았으면 하는 개인적인 생각이 있다. 통계적, 개발론적으로 완벽한 방법론을 설계했다면 그 결과에 대해서 Bias를 따지는 것은 무의미하다.
사회에 잘못된 Bias는 분명 존재하고 AI model이 이를 학습해서 사회의 잘못된 Bias를 강화시키는 것은 지양하는게 타당하다. 하지만 ‘이루다’와 같이 법률적, 통계적 근거가 아닌 프로파간다를 위한 분석이 사회에 만연했던 사례도 분명 존재한다.
‘이루다’가 가졌던 문제점들은 여러 기사들을 통해 지적됐다. 기사 링크 염두할 것은 이루다 서비스가 가졌던 개인정보보호와 법률적 문제점이지 결코 Bias된 모델에 대한 것이 아니다. 일부 집단들의 프로파간다로써 이루다 이슈가 묻힌 것은 AI를 공부하는 사람으로서 아쉬운 부분이다.
즉, 통계적, 법률적 관점을 고려하지 않고 모델의 결과만을 통해 모델이 Bias하게 개발됐다고 하는 것은 어폐가 있다고 생각한다.
Privacy
싱가포르의 COVID-19 방역을 위한 위치추적 앱인 ‘TraceTogether’ Privacy에 대해 분석하고 개선점을 제안한 논문이다. ref: https://arxiv.org/pdf/2003.11511.pdf
논문에서 주장하는 Privacy 관련 이슈는 아래와 같다.
- 사용자의 디바이스에는 본인의 정보만이 있다. 하지만 모든 사용자의 정보는 개인을 식별할 수 없는 random string으로 가려진 후 central server에 저장된다.
- Privacy from snoopers
- 개개인의 정보는 매번 바뀌는 random string을 통한 식별자로 관리되고 개인 디바이스에는 개인의 정보만이 있다. 따라서 snoofing의 위험이 있다고 할지라도 privacy에 관한 이슈는 크지 않다.
- Privacy from contacts
- 개인이 COVID-19 환자와 접촉했음이 감지된다면, 앱은 싱가포르 정부에게 해당 사실을 알린다. 하지만 개인 정보를 추적할만한 정보를 넘겨주지는 않는다. (이름, 성별 등)
** 개선점 ** 기술적인 관점에서 Privacy 보호를 위한 개선점을 논문에서는 아래와 같이 제시했다.
- 분산 서버에 개인 정보 저장
- Cryptography-based solution을 쓰자
- random noise를 추가하는 것은 privacy 보호에 도움이 안된다.
** 한국 ** 한국은 다른 나라에 비해 확진자의 수가 많지 않기 때문에 확진자의 정보를 모두 공개한다. Privacy 측면에서 좋지 않은 방법이다. 또한 확진자가 많다면 의미가 없는 방법이다.
Social Inequality
백악관에서 AI가 10년 내에 사회적으로 미칠 영향을 정리한 보고서이다. 2016년, 2018년, 2019년 보고서가 있고 ref는 2016년 보고서이다.
ref: https://ainowinstitute.org/AI_Now_2016_Report.pdf
보고서의 내용은 아래와 같다.
AI가 사회적으로 중요한 결정을 내릴 수도 있다.
- Housing
- Health insurance: 특정 질병, 유전력이 있다면 건강보험 가입 시 돈을 더 내거나 가입 불가 통보를 받을 수 있다. 기존의 건강보험도 마찬가지의 결정을 하지만, AI는 보다 잠재적인 질병, 유전력을 미리 감지해 판단할 여지가 있다.
** Benefits **
- AI를 잘 활용하는 직군들(개발자, 금융 등)
- 대규모 자원을 가용할 수 있는 집단
** Harmed**
- IT를 접근하지 못하는 취약계층
- 소규모 집단, 학교
Labor
피고용자의 일자리 감소는 필연적일 것이다. 또한 피고용자에 대한 일괄적이고 시스템적인 관리가 더욱 체계적으로 이루어질 때 피해를 입는 사례가 발생할 여지가 있다. e.g., Uber
Misinformation
News GPT-3와 같이 사람과 같은 글을 쓰는 language model은 가짜 뉴스의 폭발적인 생산 가능성을 가지고 있다. ref: https://tinkeredthinking.com/?id=836
Deepfakes ref: https://arxiv.org/pdf/2001.00179.pdf 1세대 GAN이 어색한 이미지를 생성했던 것에 비해 2세대 이상의 GAN에서는 매우 자연스러운 이미지를 생성한다. 이에 대한 피해를 막고자 face replacement detection에 대한 논문이다.
Identity
Identity Prediction ref: https://www.pnas.org/content/pnas/110/15/5802.full.pdf 사용자의 페이스북 좋아요를 분석해서 사용자에 대한 정보(age, gender, political)를 예측하는 논문이다.
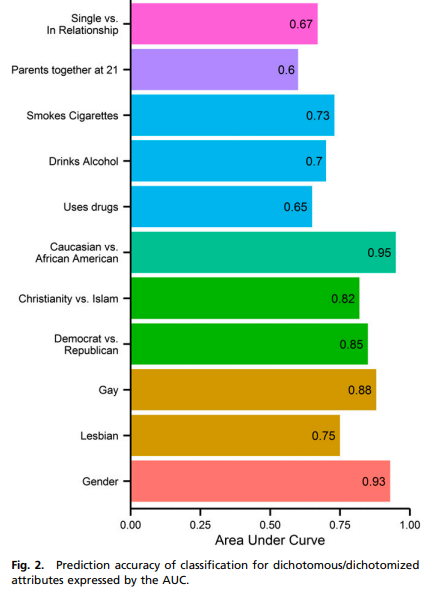
꽤 다양한 정보에 대해서 예측이 가능하고, 의미 있게 예측한다.
** Detecting cheaters in coding test **
ref: https://dl.acm.org/doi/abs/10.1145/3386527.3406726
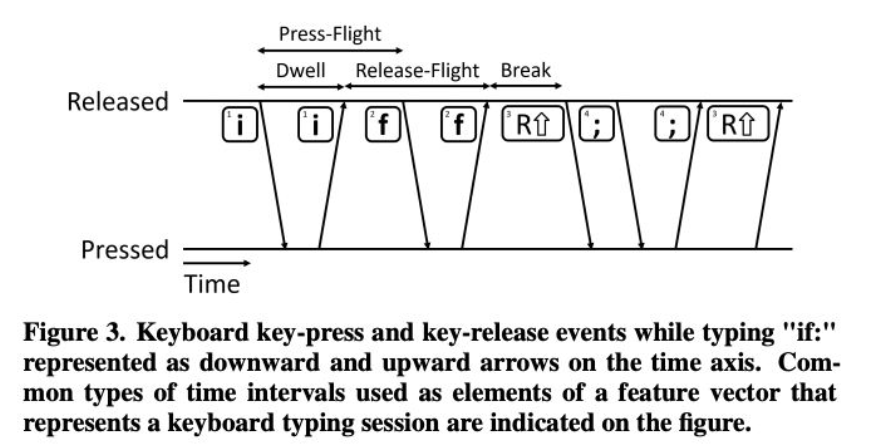 코테에서 부정행위자를 검출하기 위한 논문이다. Keystroke를 감지해서 사용자를 분류한다고 한다.
코테에서 부정행위자를 검출하기 위한 논문이다. Keystroke를 감지해서 사용자를 분류한다고 한다.
Health
** Early detection ** 당뇨병 환자 중 시력을 잃는 합병증에 걸리는 사례가 있는데, 이러한 경우를 사전에 빠르게 탐지하는 기술이 개발됨. ref: https://irisvision.com/diabetic-retinopathy/
** 영상 판독 ** ref: https://youtu.be/Mur70YjInmI 영상 판독을 통한 암 판별에도 사용되어 진료에 도움이 된다고 한다. 개인적으로 이러한 사례에 대해서 CV를 통해 절대적인 해결방법을 찾았다고 생각하는 개발자들이 있는데, 나는 이러한 사례들이 아직까지는 보조 도구로써만 사용되어야 한다고 생각한다. 실제로 현재 법률 제한 또한 의학적 판단도구보다는 의학 관련 보조 도구로써 분류된다.
** COVID-19 Detection ** ref: https://www.nature.com/articles/s41591-020-0931-3 여러 DL 모델을 조합해 COVID-19를 탐지하는 모델에 대한 논문이다.
Climate change
** $CO_2$ 배출 ** ref: https://s10251.pcdn.co/pdf/2021-bender-parrots.pdf AI와 환경오염과 관련되어서 빠지지 않는 이슈다. 한 사람이 1년에 대략 5t의 $CO_2$를 배출한다고 했을 때, 일반적인 거대 transformer를 한번 학습할 때 284t의 $CO_2$를 배출한다고 한다. 따라서 연구자들은 효율성, 성능과 더불어 engergy cost에 대해서도 고려해야 된다는게 논문의 주장이다.
** 환경에 도움이 되는 경우 ** ref: https://arxiv.org/pdf/1906.05433.pdf 긴 논문이지만 AI의 사용처에 대해 요약하면 다음과 같다고 한다.
- 탄소 연료를 사용하지 않는 경우에 대한 solution 개발
- 기존 자원에 대한 소비를 효과적으로 줄이는 solution 개발
- 전지구적으로 이러한 solution들을 어떻게 실행할지에 대한 계획 개발
- 교통수단의 에너지 효율성 증대(전기차)
- 거대 운송수단(기차, 비행기)등의 효율적인 운송시간표를 계획해 연료소비 감소
- 온수 사용 시간을 분석해 효과적으로 온수 공급
- 공용자전거의 배치를 수요에 따라 배치해서 자전거 이용량을 늘리는데 사용
- Uber의 동선을 최적화해서 짧은 동선을 게획
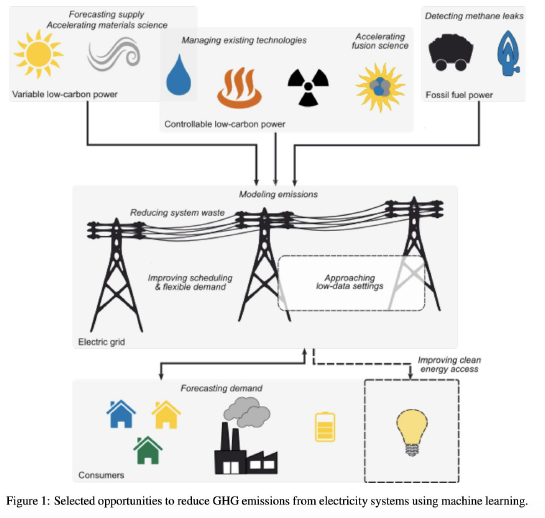
가령, 전기 소비에 대한 forecast가 효과적으로 이루어진다면 필요한 자원만큼만 배분할 수 있다. 전기와 관련된 이야기이기 때문에 자원 배분에 초점을 맞춘다기보다는 전기 생산량을 조절할 수 있다는 것이 요지인거 같다. 댐처럼 전기를 저장하는데 용이한 SoC가 존재하는 것이 아니니까..
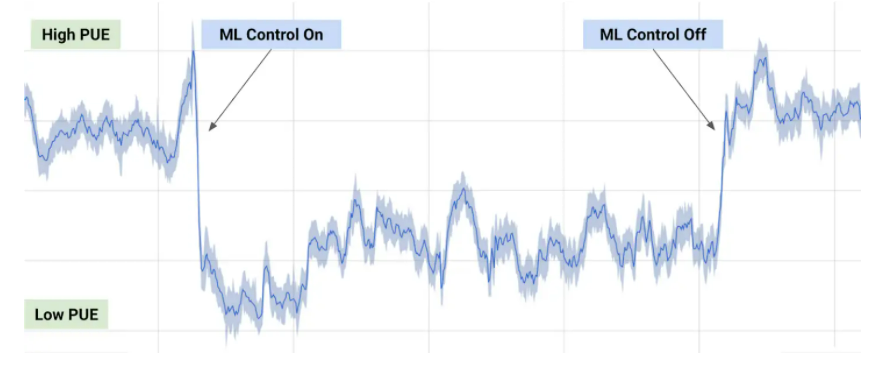 ref: https://deepmind.com/blog/article/deepmind-ai-reduces-google-data-centre-cooling-bill-40
ref: https://deepmind.com/blog/article/deepmind-ai-reduces-google-data-centre-cooling-bill-40
Deepmind에서 Google data center의 냉방 효율성에 대해서 기고한 포스팅이다. ML 관련 작업을 할 때와 하지 않을 때의 스케쥴러를 ML을 통해 분석해서 냉방 시에 소모되는 에너지를 줄이고자 하는 것이 목적이다.
Leave a comment