
Neural network
Neural network
Linear regression에서의 NN
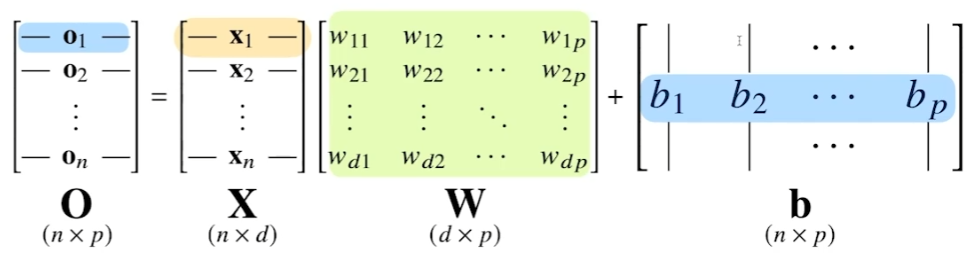
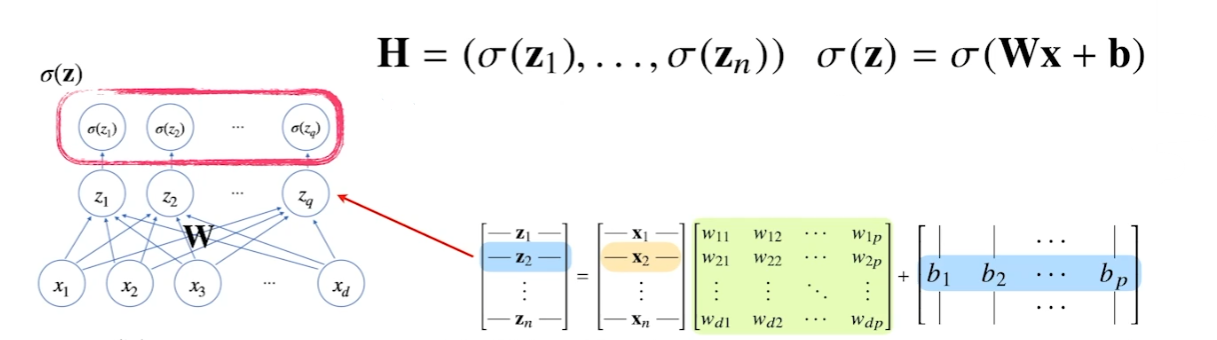
행렬의 역할을 아주 잘 활용한 전형적이 예시가 NN이다.
X 행렬에서 데이터를 모아둔다. W에서는 X의 데이터를 다른 차원으로 보내주는 역할을 한다.
b 행렬은 y 절편을 열벡터에 한꺼번에 더해주는 역할을 한다.
본래 (X, d) 차원이었던 X 행렬은 (n, p) 차원으로 변환된다.
해석
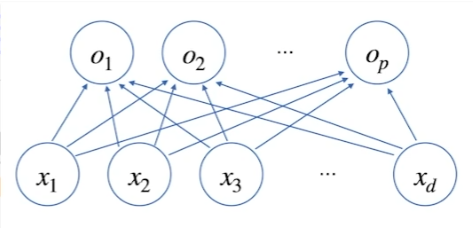
d차원이었던 X를 p차원으로 연결.
하나의 화살표는 W 벡터의 하나의 변수를 뜻한다. xd는 p개의 o를 가르키기 때문에 화살표는 d x p개만큼 존재하는데 이는 W 행렬의 차원과 동일하다.
Classification에서의 NN
Softmax
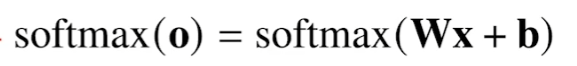
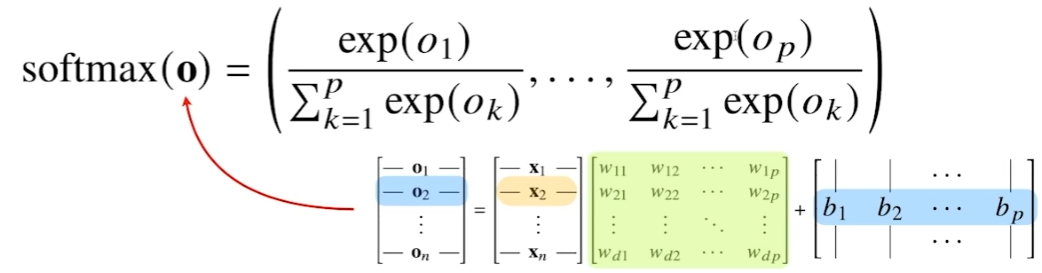
classification에서는 softmax를 벡터와 결합해 확률벡터로 표현한다. 즉, 선형 모델에 softmax를 결합하여 선형 모델의 결과를 원하는 형식대로 해석 가능하다.
Softmax 구현
def softmax(vec):
denumerator = np.exp(vec - np.max(vec, axis=-1, keepdims=True))
numerator = np.sum(denumerator, axis=-1, keppdims=True)
val = denumerator / numerator
return val
np.max를 추가해서 overflow를 방지한다. 기존의 softmax 연산결과는 보장된다.
Prediction
Prediction에서는 softmax를 사용하지 않고 onehot과 같은 메서드만을 사용한다. 이미 NN의 출력으로 확률이 나왔기 때문이라고 생각한다.
def one_hot(val, dim):
return [np.eye(dim)[_] for _ in val]
def one_hot_encoding(vec):
vec_dim = vec.shape[1]
vec_argmax = np.argmax(vec, axis=-1)
return one_hot(vec_argmax, vec_dim)
Activation function
- 활성화함수는 선형함수의 출력을 비선형으로 바꿔준다.
- 활성화 함수로 변형된 벡터 = Hidden 벡터, 잠재 벡터, 뉴런
- 신경망(NN) = 뉴런으로 이루어진 모델
- Perceptron = 뉴런으로만 이루어진 전통적인 모델
softmax와의 차이점은 softmax는 모든 변수값을 고려하지만 활성화함수는 본래 실수에 대해서만 적용된다고 한다. ?? softmax도 활성화 함수인줄 알았는데 내가 잘못 알고 있었다.
정의
실수에서 정의되는 비선형 함수. 활성화 함수를 쓰지 않은 NN은 선형모델과 전혀 차이가 없다!
종류
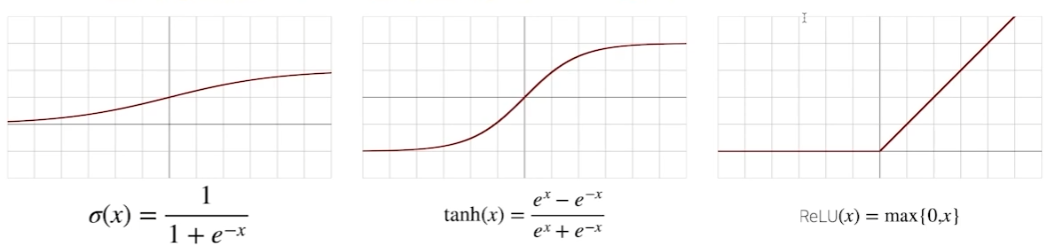
전통적으로는 sigmoid와 tanh를 사용. 최근에는 relu와 relu 변형 사용.
NN(Neural network)
정의
선형모델과 활성함수를 합성한 함수
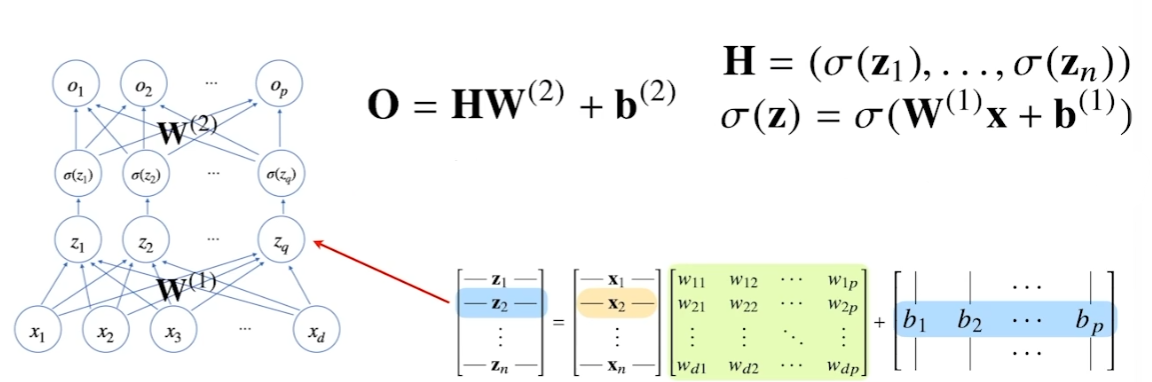
신경망 내에서의 입력 z를 잠재 벡터 h로 변환하는 과정을 반복하여 신경망의 layer를 쌓는다. 위 그림은 two layer NN이다. 이를 일반화하면 아래와 같다.
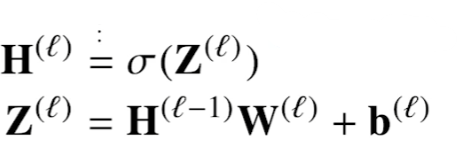
활성화 함수가 적용될 때는 위에서 언급했듯이 하나의 벡터 내의 실수에 개별적으로 적용된다.
layer를 2개 이상 쓰는 이유
universal approximation theorem
- 2층 신경망으로도 임의의 연속함수 근사 가능
- 실현이 어렵다.
층이 깊을수록 목적함수를 근사하는데 필요한 뉴런의 숫자가 급감한다.
따라서 보통 깊은 층의 NN을 사용한다. 하지만 최적화는 어려워진다.
forward propagation(순전파)
NN의 layer를 쌓는 과정을 그대로 따라가며 가중치를 조정하는 것.
back propagation(역전파)
고전파 ㅋㅋ ..
선형모델의 parameter update
선형모델은 어찌보면 1개의 layer라고도 생각할 수 있다. 즉, 모든 parameter들이 한번에 모두 업데이트된다.
NN의 parameter update
반면 NN은 여러 개의 layer로 구성된다. 즉, 한꺼번에 모든 parameter들을 업데이트할 수 없다. 순차적으로 진행해야 한다.
원리
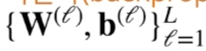 최종 목표 : L개의 모든 층에 사용된 모든 paratmer를 업데이트
최종 목표 : L개의 모든 층에 사용된 모든 paratmer를 업데이트
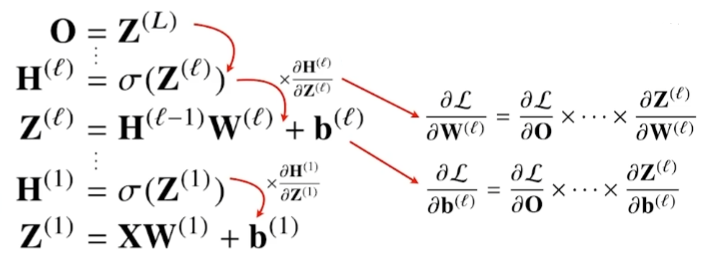
미분의 연쇄작용을 사용하여 출력단에서 입력단까지 거꾸로 거스르면서 parameter를 업데이트한다.
chain-rule기반 자동미분(audo-differentitaion)
미분의 chain-rule은 고등학교 때 배웠던 내용 그대로이다.
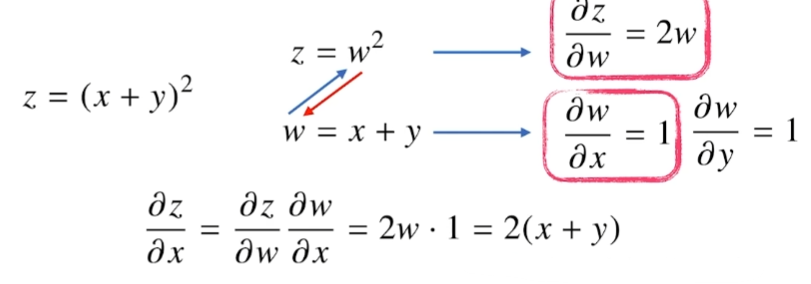
이 때, 컴퓨터가 각 node의 텐서들을 알고 있어야지 chain-rule을 통한 계산이 가능하다.
반면 forward propagation은 단순히 순차적으로 계산하면 되기 때문에 메모리적으로 back propagation보다 유리하다.
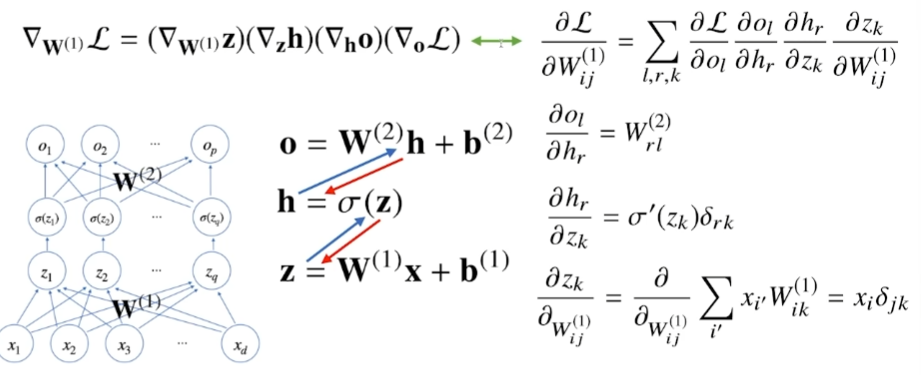
위 그림에서 파란색 화살표가 forward propagation, 빨간색 화살표가 back propagation이다. W1에 대한 gradient vector를 구하기 위해 chain-rule을 사용한 과정을 보여주고 있다.

Leave a comment