
Reducing Training Bias
Definition of Bias
Bias는 지양대상이 아니다. 하지만 일부 bias로 인해 모델의 성능에 악영향을 끼치는 경우가 있고, 이러한 bias issue는 해결해야 한다.
- ML/DL
- inductive bias(ref)
- 학습 시에는 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용하는 추가적인 가정 (additional assumptions)
- 사전 지식을 주입하기 위해 특정 형태의 함수를 선호하는 것
- 개발자가 모델을 디자인하고 데이터를 모델에 맞게 주입하는 것 자체가 일종의 편향성을 가진다는 것
- inductive bias(ref)
- 실제 세계
- Historical Bias
- 현실 세계 자체가 편향된 성향을 가진다면 모델 또한 편향된 성질을 가질 것이다.
- Co-occurrence bias
- 성별, 직업 등 표면적인 상관관계 때문에 원치 않는 속성이 학습되는 것
- Historical Bias
- Data generation
- Specification bias
- 입력과 출력을 정의하는 방식에서 발생되는 편향
- Sampling bias
- 데이터를 샘플링하는 방식 때문에 생기는 편향
- Annotator bias
- annotator 자체의 특성 때문에 발생하는 편향
- Specification bias
Gender bias
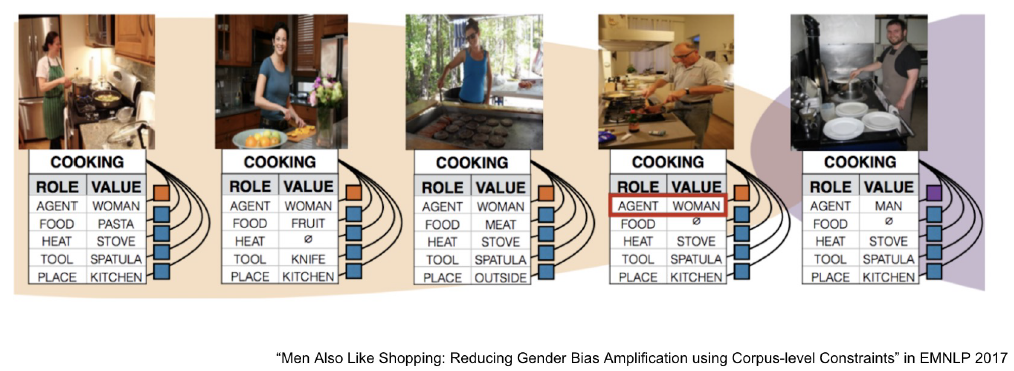
사진을 보고 여러 속성을 추출하는 모델이다. Cooking과 여성의 사진이 train data에 많이 포함됐기 때문에 남자가 요리를 하고 있음에도 여자라고 판별하는 경우가 많았다고 한다.
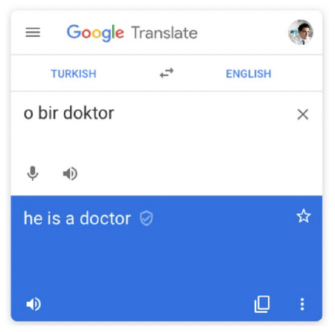 https://ai.googleblog.com/2020/04/a-scalable-approach-to-reducing-gender.html
https://ai.googleblog.com/2020/04/a-scalable-approach-to-reducing-gender.html
‘어떤 사람이 의사다’라는 단어를 터키어에서 영어로 번역하면 ‘he’로 특정된다고 한다. 구글이 의도하지 않았다고 할지라도 train data에서 의사와 남자에 대한 상관관계가 많이 존재했다면 위와 같이 정확하지 않은 assumption을 하게 된다. 사회적인 문제라기 보다는 정확하지 않은 모델 출력의 문제라고 생각한다.
Sampling bias
Biased한 방식으로 sampling하게 된다면 표본이 모집단의 성질을 반영한다는 신뢰성이 사라진다. Random하고 fair하게 sampling할 수 있도록 하자.
Bias in ODQA
Reader model은 train data에서 항상 정답이 문서 내에 포함된 데이터 쌍에 대해서만 positive라고 학습할 것이다. e.g.,) SQuAD의 positive는 (Context, Query, Answer)가 고정됨.
따라서 Reader model은 positive가 아닌 전혀 다른 성질의 데이터 쌍에 대해서 독해 능력이 매우 떨어질 것이다. e.g.,) 소설, 수필, 비문학 등의 train data로 학습된 reader model은 의학, 공학, 자연과학에 대한 inference에서 성능이 매우 떨어질 것이라고 예상할 수 있다.
Mitigate training bias
- Train negative examples
- negative example을 통해 negative input data를 정답과 먼 곳에 배치 가능
- random하게 뽑기보다는 헷갈리는 negative samples를 뽑도록 하자
- 마치 dense embedding에서 최대한 비슷한 문서들을 통해 negative sample을 뽑은 것처럼
- 높은 BM25/TF-IDF score지만 답을 포함하지 않은 sample을 활용
- 같은 문서에서 나온 다른 passage/question을 활용
- Add no answer bias
- no answer에 대한 경우를 처리해야 한다.
- input sequence 외에 1개의 token이 더 있다고 가정
- answer prediction에서 start, end 확률이 해당 bias에 있을 경우 no answer로 취급.
Annotation Bias from Datasets
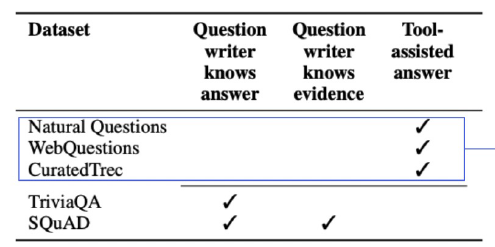
질문을 하는 사람이 answer를 모른다는 시나리오대로 dataset이 만들어져야 한다. 왜냐하면 question 자체에 answer에 대한 내용이 포함되거나 answer에 대한 힌트가 너무 많이 담겨있을 수도 있기 때문이다.
위 표에서 이러한 dataset의 예시는 파란색 박스 안의 datsets다.
하지만 질문을 하는 사람이 answer를 알고 있는 상태의 시나리오로 데이터 annotation이 발생할 수도 있다. 대표적인 예시가 TriviaQA와 SQuAD다.
SQuAD의 경우 question과 evidence paragraph에서 많은 단어들이 겹치는 bias가 발생한다. 따라서 모델은 독해 능력을 키워서 답을 찾는 것이 아니라 단순히 단어 맞추기를 위한 학습을 진행할 수도 있다. 물론 이러한 행위가 잘못된 것은 아니지만 모델의 독해 능력 향상을 원한다면 의도된 학습 방향이라고 할 수 없다.
또한 SQuAD는 사람들이 가장 많이 보는 wiki article의 500개 문서를 train data로 사용하고 있다. 따라서 해당 문서에 대해 bias가 심할 것이다.
Efficient of annotation bias
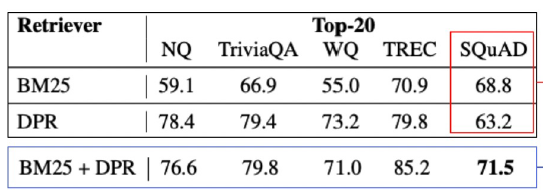
annotation bias가 존재하는 dataset에 대해서는 객관적인 평가가 이루어지 어렵다. 위 표에서 대부분의 모델들은 DPR을 사용했을 때 더 좋은 score가 나오지만, SQuAD의 경우만 BM25에서 가장 좋은 성능을 보여준다. 왜냐하면 question과 evidience 사이의 overlapped 단어들이 SQuAD는 많기 때문이다.
이에 대한 해소법으로 BM25, DPR 두 방법을 모두 사용할 수 있다. 이것 또한 annotation bias가 발생된 dataset에 대한 해소법이고 다른 모델들의 경우 오히려 두 방법을 혼용하니 score가 떨어지는 경우도 있었다. dataset에 따라서 적절하게 시도를 해보자.
Dealing with annotation bias
Annotation bias를 방지하기 위한 datset을 사용하자. e.g., Natural Quesitons는 구글 검색 엔진에서 Supporting evidence가 주어지지 않은 실제 유저의 question을 통해 dataset을 구성했다. ODQA와 최대한 비슷한 세팅이기 때문에 Annotation bias를 많이 해소했다고 볼 수 있다.
ODQA에 적합하지 않은 질문들은?
“미국의 대통령은?”이라는 question은 MRC에서는 풀 수 있는 종류의 문제라고 할지라도 ODQA에서는 아닐 수도 있다. 왜냐하면 현재 대통령을 묻는 것인지, 모든 대통령의 리스트를 원하는 것인지, 과거의 특정 대통령을 원하는 것인지 전혀 모르기 때문이다.
이러한 종류의 질문들에 대한 처리도 필요하다.
Leave a comment