
경량화 overview
Goal
On device AI
- 사용자 개인 기기에 탑재되는 모델들이 가지는 제한사항을 극복
- power usage
- RAM
- Storage
- Computing power
AI on cloud
- 많은 사용자가 사용해야 하기 때문에 latency, throughput이 중요한 이슈
- e.g., 요청당 소요시간, 단위 시간당 처리 가능한 요청 수
- 동일 자원으로 더 적은 latency, 더 큰 throughput을 구현/구축해야한다.
Computation
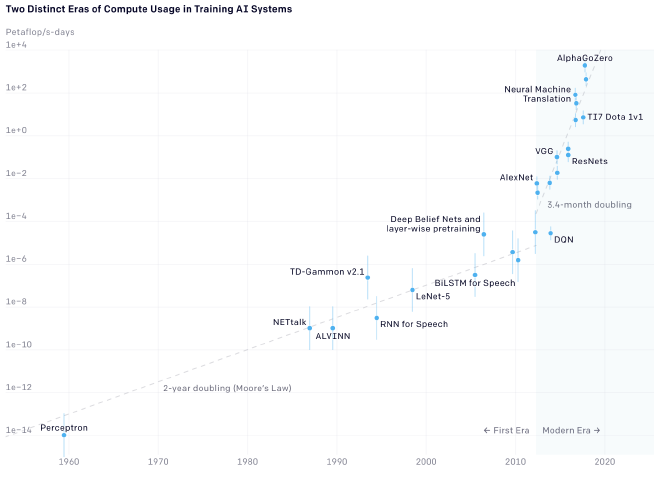
- 모델 자체의 연산 수행 횟수를 줄여야한다.
- 2012년 이후로 모델 학습에 소요되는 연산은 3, 4개월마다 두 배씩 증가
Efficient Architecture Design
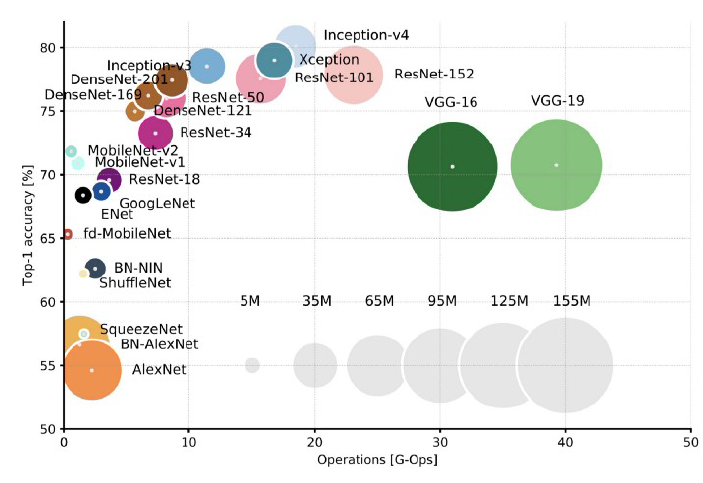 출시된 CNN 모델들의 파라미터 수와 성능에 대한 도표다. 위 도표에서 출시된 모델들은 파라미터수를 효율적으로 줄이면서 성능을 높이려고 했다. 이러한 것들의 대표적인 Efficient Architecture Design이다. 즉, 모델 자체를 효율적으로 설계하고자 하는 것이다.
출시된 CNN 모델들의 파라미터 수와 성능에 대한 도표다. 위 도표에서 출시된 모델들은 파라미터수를 효율적으로 줄이면서 성능을 높이려고 했다. 이러한 것들의 대표적인 Efficient Architecture Design이다. 즉, 모델 자체를 효율적으로 설계하고자 하는 것이다.
AutoML;Neural Architecture Search(NAS)
알아두면 써먹을 곳이 많은 유용한 기법!
사람이 아니라 알고리즘을 통해 효율적인 모델을 설계하거나 찾아보자.
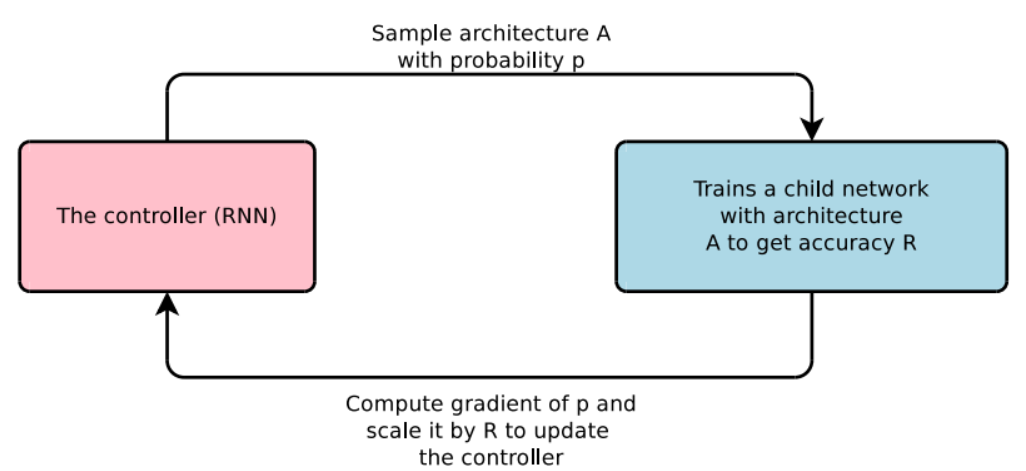
controller는 모델 아키텍쳐를 제시하는 모델이다. controller에서 제시된 모델로 accuracy를 구해보고 이 수치를 활용해 controller를 재학습한다. 이러한 과정을 반복해서 효율적인 모델을 찾아볼 수 있을 것이다.
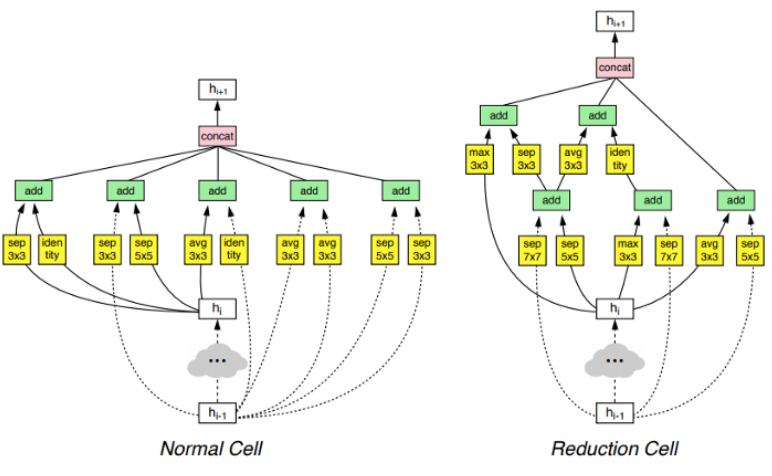
AutoML, NAS를 통해 얻은 모델은 사람의 직관으로 이해할 수 없는 모델일 가능성이 높다. 그럼에도 이러한 모델의 성능이 기존 모델보다 높을 수도 있다.
Network Pruning
- 중요도가 낮은 모델의 파라미터를 제거
- topic: 좋은 중요도를 정의, 찾기
- e.g., 임의의 파라미터의 L2 norm이나 loss gradient를 계산해서 중요도를 계산한다.
- structured/unstructeured pruning으로 나뉜다.
Structured pruning
- 파라미터를 그룹 단위로 pruning하는 기법들을 총칭
- 그룹: channel, filter, layer 등
- 한꺼번에 pruning하기 때문에 Dense computation에 최적화된 SW/HW에 적합한 기법
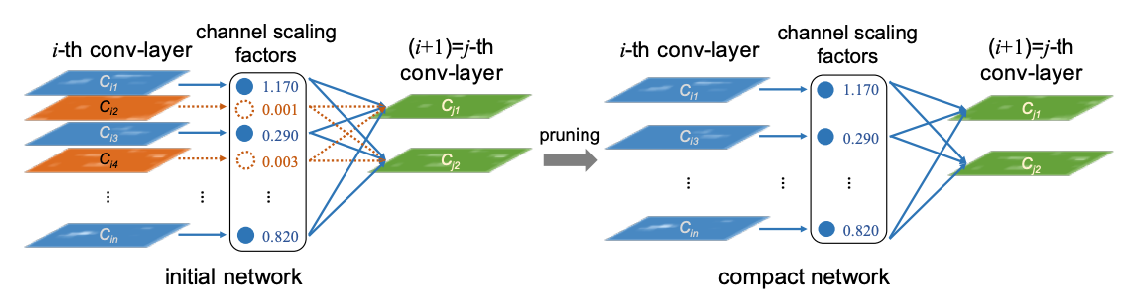 기존 네트워크에 대해서 channel별로 그룹을 지어서 layer별 factor를 계산한다. 낮은 중요도를 가지는 layer를 지워버리면 경량화된 모델을 만들 수 있다.
기존 네트워크에 대해서 channel별로 그룹을 지어서 layer별 factor를 계산한다. 낮은 중요도를 가지는 layer를 지워버리면 경량화된 모델을 만들 수 있다.
Unstructured prunig
- 파라미터 각각을 독립적으로 pruning
- 개별적으로 적용되기 때문에 pruning을 수행할수록 네트워크 내부 행렬이 희소(sparse)해진다.
- sparse computation에 최적화된 SW/HW에 적합
Knowledge Distillation
Pre-trained된 큰 모델을 작은 네트워크의 학습 보조로 사용
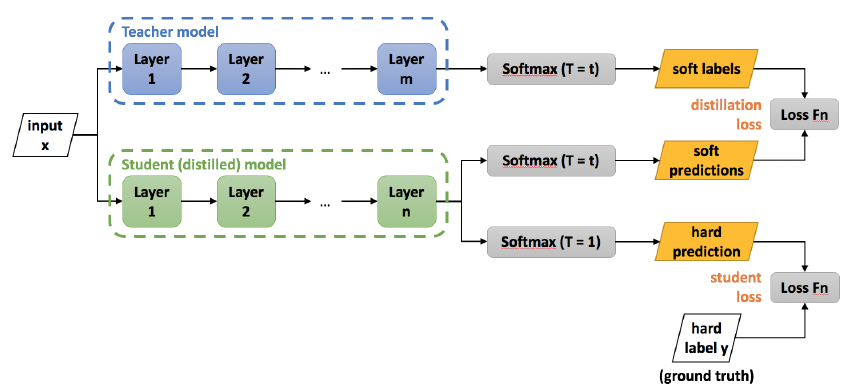 student loss 부분은 기존의 네트워크 학습 방식과 동일하다. ground truth와 prediction 결과를 활용해 loss를 구한다.
distillation loss 부분이 knowledge distillation이 발생하는 부분이다. ground truth가 아니라 teacher model을 통해 얻은 soft label을 활용해서 prediction과의 loss를 구한다.
student loss 부분은 기존의 네트워크 학습 방식과 동일하다. ground truth와 prediction 결과를 활용해 loss를 구한다.
distillation loss 부분이 knowledge distillation이 발생하는 부분이다. ground truth가 아니라 teacher model을 통해 얻은 soft label을 활용해서 prediction과의 loss를 구한다.
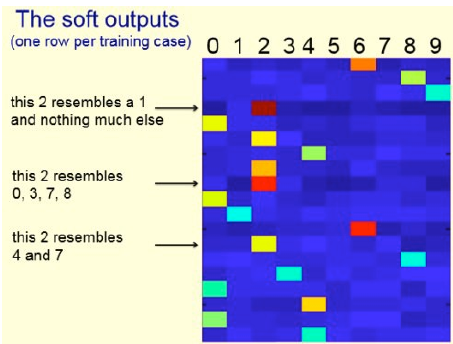 soft targets(soft outputs)에는 ground truth보다 더 많은 정보를 담고 있다. 위 그림은 row별로 예측된 label을 표시할 때 probability를 색깔로 표현한 것이다. ground truth와 다르게 classification의 예측값 1개만을 사용하지 않고 모든 label에 대한 probability를 활용할 수 있게 된 것이다.
따라서 더 많은 정보를 활용해 작은 네트워크를 학습 가능하다.
soft targets(soft outputs)에는 ground truth보다 더 많은 정보를 담고 있다. 위 그림은 row별로 예측된 label을 표시할 때 probability를 색깔로 표현한 것이다. ground truth와 다르게 classification의 예측값 1개만을 사용하지 않고 모든 label에 대한 probability를 활용할 수 있게 된 것이다.
따라서 더 많은 정보를 활용해 작은 네트워크를 학습 가능하다.
수식
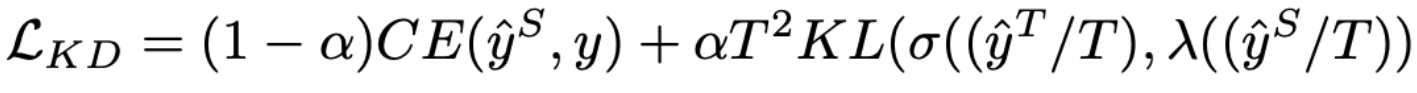
- 왼쪽 항: student network, ground truth의 cross-entropy
- 오른쪽 항: teacher network와 student network의 KLD loss
- $T$: temperature hyperparameter. softmax의 결과가 작다면 크게, 크다면 작게 만들어준다.ref
- $\alpha$: 두 loss에 대한 가중치
Matrix/Tensor Decompostion
수학적으로 복잡하지만 간단한 기법만 적용하더라도 유효한 성능을 낼 수 있는 기법
- 하나의 tensor를 작은 tensor들의 합/곱으로 표현
Cp decomposition
rank 1 vector들의 output product의 합으로 tensor를 approximation.
Network Quantization
fp32를 fp16, int8로 mapping.
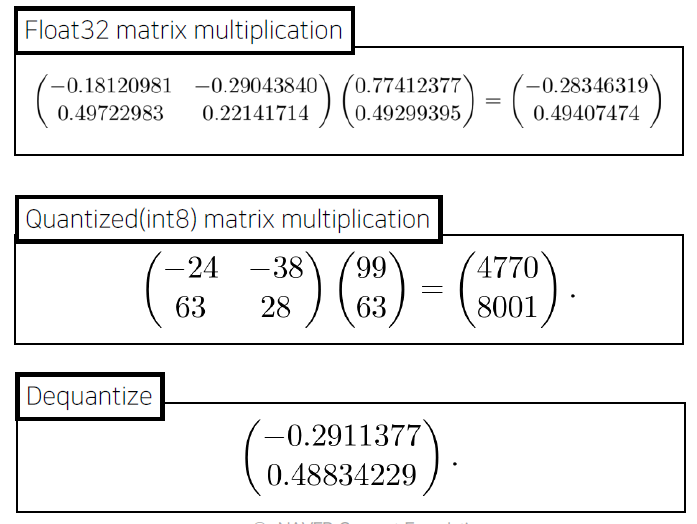
Quantization을 적용 후, 연산 결과에 대해서 Dequantization을 수행하면 fp32의 결과와 비교해서 error가 발생할 것이다. 하지만 경험적으로 이러한 error에 대해서 모델이 robust하게 잘 동작한다고 알려져 있다.
- model size: 감소
- acc: 약간 하락
- time: HW에 따라서 다르다. 전반적으로 HW와 무관하게 향상되는 추세
- e.g., 특정 HW에서는 int8 quantization이 더 느릴수도 있다.
Network compiling
- target system이 고정됐을 때, 효율적인 연산을 하도록 네트워크 자체를 컴파일.
- 속도에 가장 큰 영향을 미치는 기법
- TensorRT(NVIDIA), Tflite(Tensorflow), TVM(apache)
- compile library, HW system, model 조합별로 성능이 상이하다.
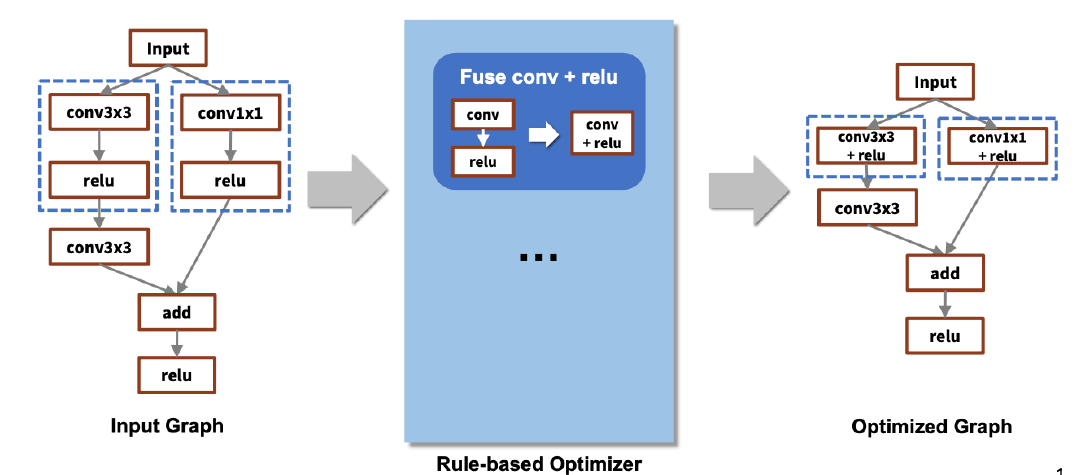
rule-based로 compiling을 수행하면 위와 같이, 정의된 rule에 따라서 graph를 간소화시킨다. 간소화시킨 결과물을 fusion이라고 부른다.
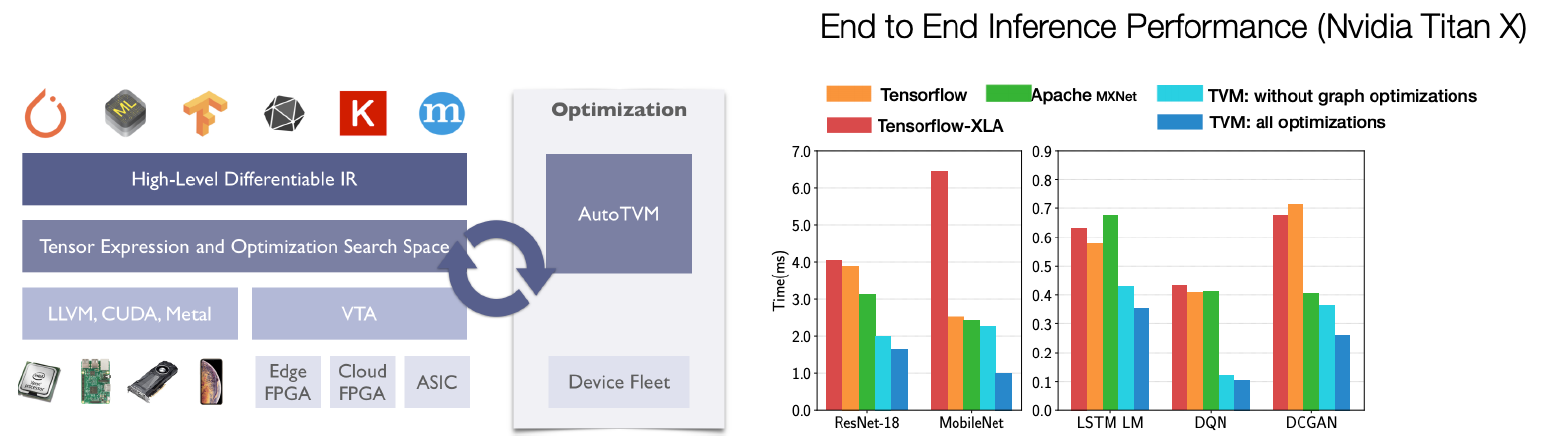
AutoML로 graph의 좋은 fusion을 만들고자 하는 시도도 있다. framework, HW, system을 모두 고려하면 굉장히 많은 조합이 발생할 수 있다. 따라서 target system에 대해 최적화된 fusion을 찾기위해 AutoML을 사용하는 것이다. Apahce에서 출시한 AutoTVM이 그러한 역할을 한다고 한다.
Leave a comment