
베이즈 통계학
이것도 고등학교 때 배운 내용들이 많은데 까먹은 것도 많다…
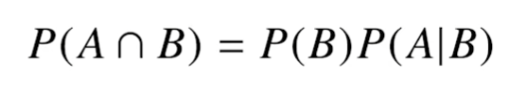
위 조건부확률은 사건 B가 일어났을 때, 사건 A가 발생할 확률을 의미.
베이즈 정리
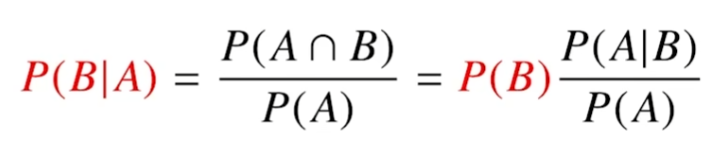
위 수식은 A라는 새로운 정보가 주어졌을 때, P(B)로부터 조건부확률을 계산하는 방법을 제공한다.
베이즈 정리 예제

- D : 새로 관찰하는 데이터
- Θ : hypothesis, 모델링하는 이벤트, 모델에서 계산하고자 하는 parameter
- 사후확률(posterior distribution) : D가 관찰됐을 때, Θ가 성립할 확률, 데이터를 관찰한 후이기 때문에 사후라고 한다.
- 사전확률(prior distribution) : D가 관찰되기 이전에, 사전에 관찰되는 Θ의 확률. 미리 가정된 모수, 확률 분포.
- 베이즈 정리의 분자 : likelihood
- 베이즈 정리의 분모 : Evidence, 데이터 자체의 분포
베이즈 정리 예제(COVID-99)
COVID-99의 발병률이 10%이다. COVID-99에 실제로 걸렸을 때, 검진될 확률은 99%이다. COVID-99에 실제로 걸리지 않았을 때, 오검진될 확률이 1%이다. 이 때, 어떤 사람이 COVID-99에 걸렸다고 검진결과가 나왔을 때, 실제로 COVID-99에 감염되었을 확률은?
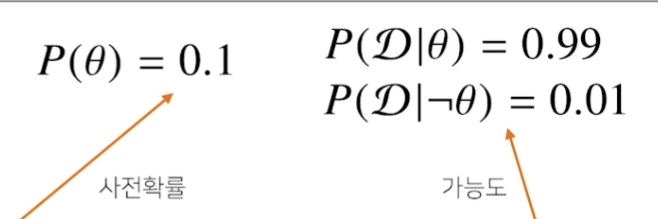
Θ를 COVID-99 발병 사건으로 정의(관찰 불가) D를 테스트 결과라고 정의.
Θ와 ¬Θ에 대한 사건확률을 위와 같이 정의할 수 있다.
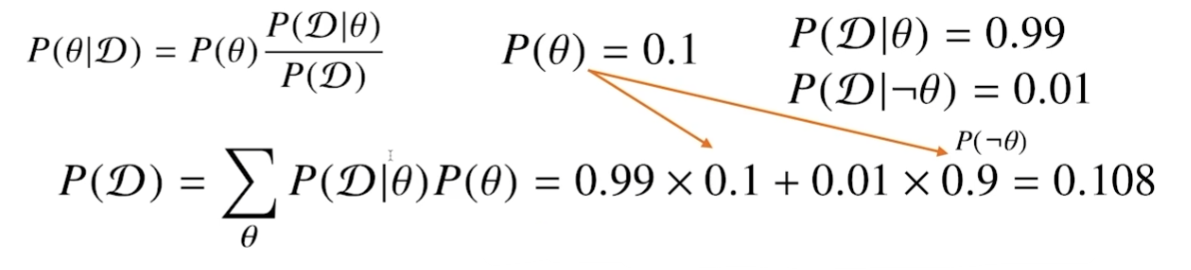
베이즈 정리를 활용해서 Evidence를 구하기 위해 위와 같이 식을 세워볼 수 있다. Likelihood에 Θ의 확률을 곱해주어 더하자.
조건부확률의 시각화
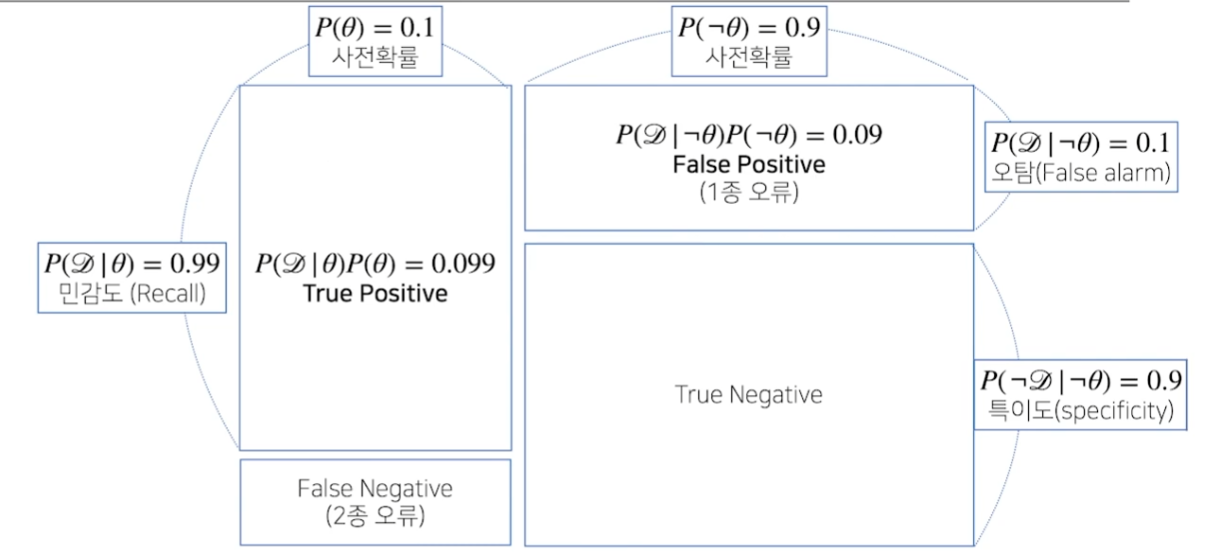
True Positive : Recall._양성이라고 판별됐을 때, 실제로 양성일 확률. True Negative : 음성이라고 판별됐을 때, 실제로 음성일 확률 False Positive : _False alarm(1종 오류). 양성이라고 판별됐을 때, 양성이 아닌 확률. False Negative : _(2종 오류)._음성이라고 판별됐을 때, 음성이 아닐 확률.
- 사전 확률 P(Θ)에 따라서 Recall이 결정된다.
- 사전 확률 없이는 베이즈 통계를 활용할 수 없다.
- 사전 확률을 모르는 경우, 임의로 설정할 수 있지만 신뢰도가 매우 떨어진다.
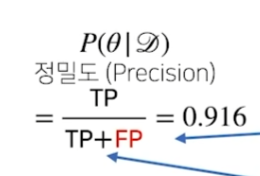
Precisoin은 위와 같이 계산한다.
조건부확률의 활용
가령, 암환자 탐지에 대한 문제라고 하자. 이럴 때는, 2종 오류를 줄이는 것이 매우 중요하다. 암환자가 아니라고 판별했지만 실제로는 암화자인 경우가 2종 오류이기 때문이다.
따라서 1종 오류와 2종 오류 사이의 균형을 맞출 때, 2종 오류에 더욱 민감하게 신경을 써야 한다.
베이즈 정리를 통한 정보의 갱신

이전 step의 사후확률을 다음 step의 사전확률로써 사용 가능하다.
용례
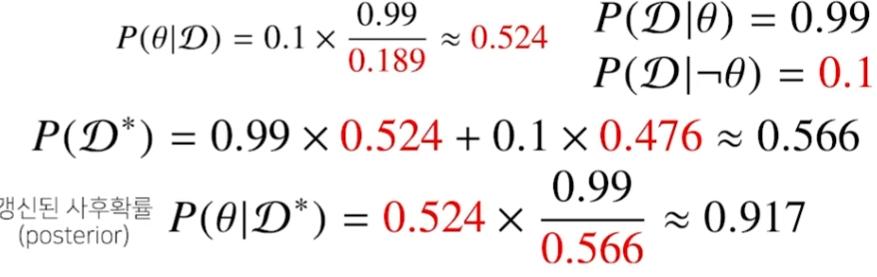
COVID-99 검사할 때 첫번째 검진 시, 제대로 탐지할 확률은 52.4%였다. 동일한 사람에게 연속해서 한번 더 검사를 할 경우 91.7%로 검진 확률이 올라간다.
이전 step에서 산출한 사후확률인 52.4%를 다음 step의 사전확률로써 사용한 용례이다.
인과관계(casuality)에 대한 해석
조건부확률을 통해서만 인과관계를 전부 설명하는데 함부로 사용하면 안된다!!
또한 데이터가 아무리 많아진다고 하더라도 조건부 확률을 통해서만 인과관계를 설명할 수 없다.
설명할 수 있는 경우도 있겠지만, 항상 그렇다는 보장은 결코 없다. 매우 많은 데이터 분석을 통해서만 인과관계가 드러난다.
인과관계를 활용한 강건한 모델
보통 모델을 구성하면 다음과 같은 결과를 나타낸다.
- 조건부확률 기반 예측모형(99% 예측정확도)
- 기존 시나리오(95% 예측정확도)
- 변화된 시나리오(72% 예측정확도)
- 인과관계 기반 예측모형(85% 예측정확도)
- 기존 시나리오(83% 예측정확도)
- 변화된 시나리오(82% 예측정확도)
조건부 확률만을 사용한 모델들은 보통 예정된 시나리오에서는 높은 예측 정확도를 보장한다. 하지만 데이터 분포가 크게 변하면 예측정확도는 매우 낮아진다.
인과관계만을 고려한 모델은 높은 예측 정확도를 보장하진 않는다. 하지만 변화에 강건한다.
인과관계
데이터 분포의 변화에 강건한 예측모형을 만들 때 사용.
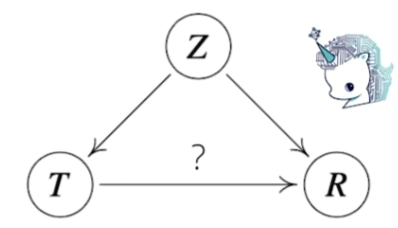
인과관계를 알기 위해서는 T와 R에 모두 영향을 주는 중첩 요인(confounding factor)인 Z를 반드시 제거해야 한다. 만일 Z를 제거하지 않으면 가짜 연관성(spurious correlation)이 나온다.
인과관계 추론의 예제

가령, 치료법 a, b에 대한 신장 결석 치료 결과를 분석해보자. 개별적인 치료법의 완치율은 a가 높지만, overall 완치율은 b가 높다. 이것이 _Simson’s paradox_이다.
이는 조건부 확률만으로 해결할 수 없다. 즉, 신장 결석 크기가 유발하는 중첩 요인을 제거해야만 실제 완치율을 분석하는 것이 가능하다.
Z의 개입 제거
do(T=a)라는 조정(intervention)효과를 통해 z의 개입을 제거한다.
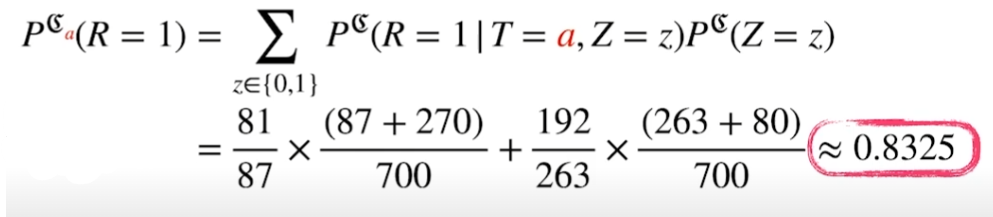
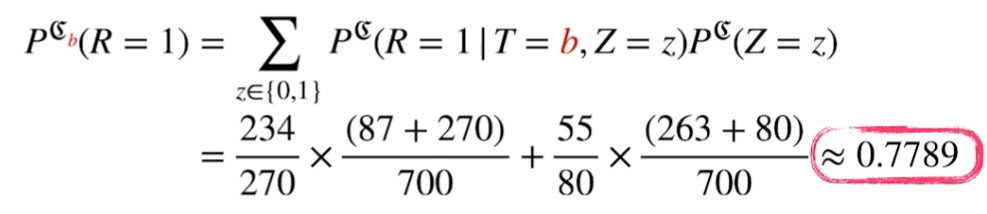
Leave a comment