
Airflow and Kubernetes
ref: Line Engineering Blog - Airflow Kubernetes - 1, Line Engineering Blog - Airflow Kubernetes - 2
Airflow와 Kubernetes를 함께 사용하는 방법은 두 가지가 있다. 각자 장단점이 있고, 서비스와 자원량에 적합한 방법을 쓰면 된다.
Airflow on Kubernetes
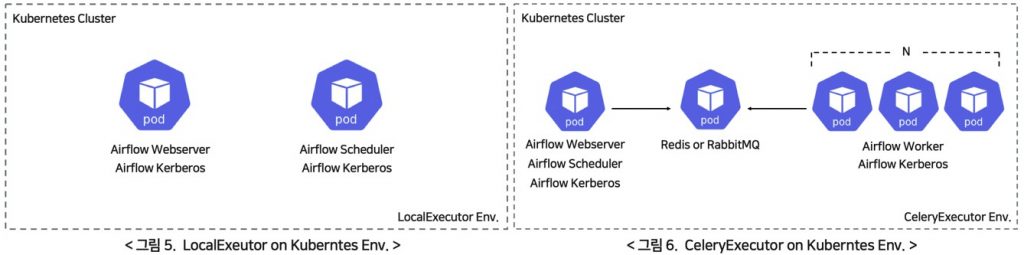
Kubernets 위에 Airflow를 구성. Airflow scheduler, Airflow Worker 등 Airflow의 component들이 본래 프로세스나 하드웨어 장비 형태였다면, 여기서는 POD 형태로 구성 된다.
Airflow on Kubernetes의 장점
모든 것이 Kubernetes 상에 있기 때문에 템플릿화가 용이하다. 따라서 관리형 Airflow 서비스 개발에 좋다.
e.g., GCP의 Cloud Composer.
Kubernetes의 orchestration을 사용할 수 있다.
Airflow on Kubernetes의 단점
POD만으로 변환되기 때문에 Celery Executor를 사용한다면 master, message, broker, worker 등이 모두 Kubernetes 환경에 지속적으로 상주해야 한다.
또한 확장성의 문제가 있다. Airflow container 내에서 여러 확장이 발생할 경우, docker 이미지도 커질 뿐더러 유지 보수/관리가 힘들어진다.
e.g., Airflow container 내에 Hadoop client가 1개 있었는데, n개로 늘어나면 n개에 대한 환경 설정과 테스팅을 해줘야한다.
KubernetesExecutor & KubernetesPodOperator
KubernetesExecutor는 Airflow가 필요할 때만 Kubernetes 환경을 사용하도록 해준다. 또한 KubernetesPodExectuor는 필요한 Docker 컨테이너만을 골라서 POD로 실행할 수 있다.
둘은 서로 종속되지 않는 기능들이다.
Kubernetes Executor
Kubernetes Executor의 동작은 일반적인 Operator와 KubernetesPodOperator로 나뉜다.
일반적인 Operator
PythonOperator, BashOperator, ExteranlTaskSensor 등…

- 수행할 task를 scheduler가 찾는다.
- Executor가 동적으로 Airflow worker를 POD 형태로 실행
- 해당 Worker POD에서 개발자가 정의한 task를 수행
Pod Operator
KubernetesPodOperator의 실행 순서는 아래와 같다.

- 수행할 task를 scheduler가 찾는다.
- Executor가 동적으로 Airflow worker를 POD 형태로 실행
- 해당 Worker POD에서 개발자가 정의한 컨테이너 이미지를 POD 형태로 또다시 실행. -> 하나의 Airflow 환경에서 다양한 클라우드에 접근 가능
장점
- 가볍다
- 라이브러리 의존성이 없는 가벼운 이미지로도 실행 가능
- 기존에는 Airflow 장비 혹은 컨테이너에 Hadoop 클라이언트, Spark 클라이언트, Hive 클라이언트, Sqoop 클라이언트, Kerberos 설정 등을 모두 구성해야 했다. 하지만 KubernetesExecutor로 KubernetesPodOperator를 사용한다면 그렇지 않아도 된다.
- 유지보수 비용 절감
- 라이브러리 간 의존성 검사 불필요
- 다양한 데이터 플랫폼 환경에 한번에 접근 가능 -> 하나의 Airflow 환경만 있어도 됨.
- 효율적인 자원 관리
- 기존 Celery Executor를 Kubernetes에서 사용할 경우, master, worker가 자원을 지속적으로 점유.
- Kubernetes Executor의 경우 task가 실행될 경우에만 worker가 생성되고 자원이 반납.
- 개발 효율성
- DAG들이 KubernetesPodOperator라면 Workflow DAG 코드를 템플릿화 가능
단점
- 부족한 레퍼런스
- 라인 데이터 엔지니어링팀이 2019년도에 작업할 때는 레퍼런스가 부족했다고 한다. 요즘도 부족해보인다.
- 까다로운 구성
- 로깅
Worker POD가 휘발성이기 때문에 별도의 로깅 시스템을 구축해야 한다. 라인 데이터 엔지니어링팀은 GCS, S3에 저장했다고 한다. - Kubernetes 자체가 러닝커브가 높다. 사용에 난이도가 있다.
- 로깅
Leave a comment