
부스트캠프 AI Tech 2기 6주차 학습정리
6주차 학습정리
강의 복습 내용
NLP (1~9번 포스팅)
https://velog.io/@naem1023/series/NLP
과제 수행 과정 / 결과물 정리
bucketing
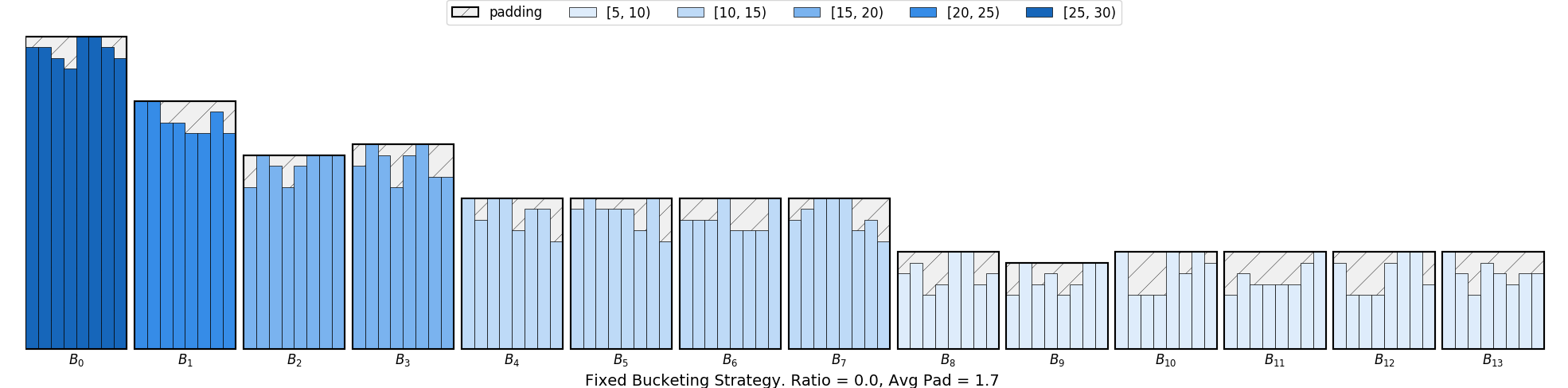 데이터의 길이에 따라서 batch를 재구성하는 기법이다.
과제 4에서 나왔는데 기법 자체에 대한 이해는 쉬웠지만, 코드에 대한 이해가 매우 어려웠다.
데이터의 길이에 따라서 batch를 재구성하는 기법이다.
과제 4에서 나왔는데 기법 자체에 대한 이해는 쉬웠지만, 코드에 대한 이해가 매우 어려웠다.
피어세션에서 해결했는데 코드에서 하고자 하는 바는 다음과 같았다.
- 데이터의 길이를 max_pad_len 단위로 바라본다.
- 가령, max_pad_len=5으로 잡고 이에 대한 몫을 활용한다고 하자. 그러면 데이터의 길이가 5 ~ 9인 데이터들은 하나의 batch로 재구성이 되도록 하고자 한다.
- 데이터 자체를 옮기면서 재구성하지 않고 데이터의 인덱스를 따로 저장하는 방식으로 batch를 재구성한다.
- 인덱스를 기준으로 batch를 재구성하고, 데이터의 길이가 같은 그룹으로 구성되는 데이터는 리스트에 인접하게 위치하도록 구성한다.
- e.g., 데이터의 길이가 5 ~ 9인 데이터들은 리스트에서 인접하도록 위치한다.
- 위의 과정이 끝나면 인덱스 리스트를 순서대로 불러오기만해도 새롭게 batch를 재구성할 수 있다.
이러한 방식이 과제 4의 bucketing 코드에 담겨있었다.
피어세션 정리
위에서 언급한 bucketing 문제에 대해서 많은 논의를 했다.
팀 구성에 대해서도 후기를 공유했다. CV와 달리 NLP는 팀구성에 굉장히 다들 의욕적이어서 구인 속도가 매우 빨랐다.
학습 회고
21/09/06: Word2Vec 공부, 과제1 해결 21/09/07: RNN, LSTM 공부, 과제2, 3 해결 21/09/08: attention 공부, 과제4 해결 21/09/09: 팀 구성에 많은 힘을 쓴 시간.. 21/09/10: 과제4 리뷰
Leave a comment