
Attention
Seq2Seq with attention
Seq2Seq with LSTM
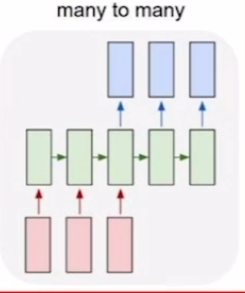 Seq2Seq는 RNN의 구조 중 many to many에 해당한다. 즉, 입출력 모두 sequenece인 word 단위의 문장.
Seq2Seq는 RNN의 구조 중 many to many에 해당한다. 즉, 입출력 모두 sequenece인 word 단위의 문장.
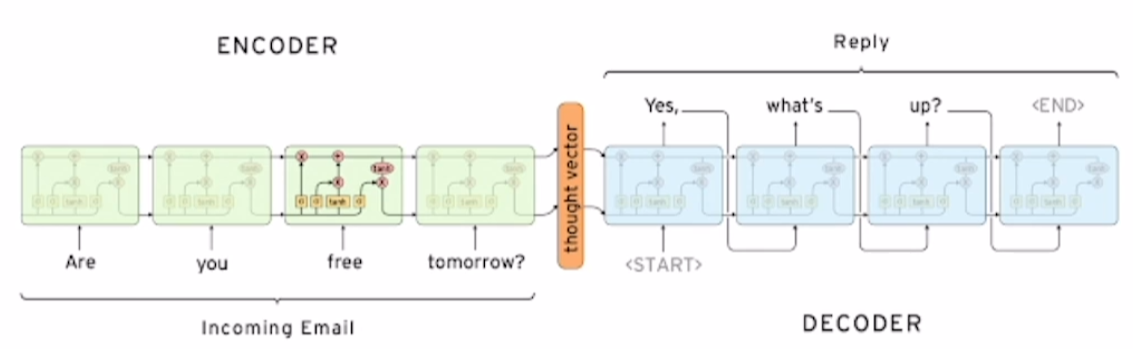 위 그림은 Dialog system(e.g., chat bot)이다. 입력 문장을 받아들이는 부분이 encoder, 출력 문장을 생성하는 부분이 decoder다.
채택한 RNN 모델은 LSTM이다. Encoder의 가장 마지막 단에서 출력된 hidden state는 decoder의 입력 hidden state로 사용된다.
위 그림은 Dialog system(e.g., chat bot)이다. 입력 문장을 받아들이는 부분이 encoder, 출력 문장을 생성하는 부분이 decoder다.
채택한 RNN 모델은 LSTM이다. Encoder의 가장 마지막 단에서 출력된 hidden state는 decoder의 입력 hidden state로 사용된다.
SoS(Start of Sentence) 생성되는 문장의 첫번째 토큰을 의미한다. SoS는 Vocabulary에서 따로 관리되는데, 학습 시 decoder의 첫번째 입력으로 넣어준다.
Eos(End of Senternce) 생성되는 문장의 마지막 토큰을 의미. 언제까지 문장을 생성할지 지정해준다.
문제점
hidden state의 고정된 dimension에 encoder의 모든 정보를 저장해야 한다. 따라서 LSTM이 아무리 long term dependency를 해결했다고 할지라도, sequence가 길어질수록 이전 정보들은 소실되거나 변질될 가능성이 다분하다.
가령, ‘I go home’과 같은 문장에서 주어를 먼저 인식해야한다. 하지만 주어는 문장의 가장 앞에 보통 위치하기 때문에 해당 정보가 뒤로 갈수록 변질되어서 주어 부분을 decoder에서 제대로 생성하지 못하는 문제가 발생할 수도 있다.
차선책 문장의 순서를 뒤집는다. ‘I go home’이면 ‘home go I’와 같이 중요한 정보를 뒷단에 배치하는 식으로 순서를 바꾸는 방식이다. 근본적인 해결책은 아니다.
해결책 step 별로 발생하는 hidden state를 모두 활용하자.
Seq2Seq with Attention
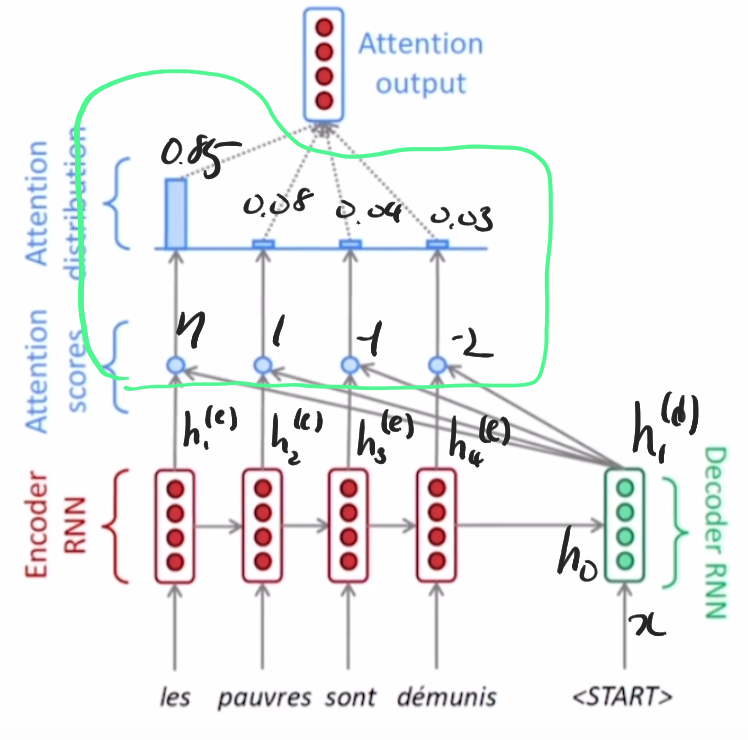
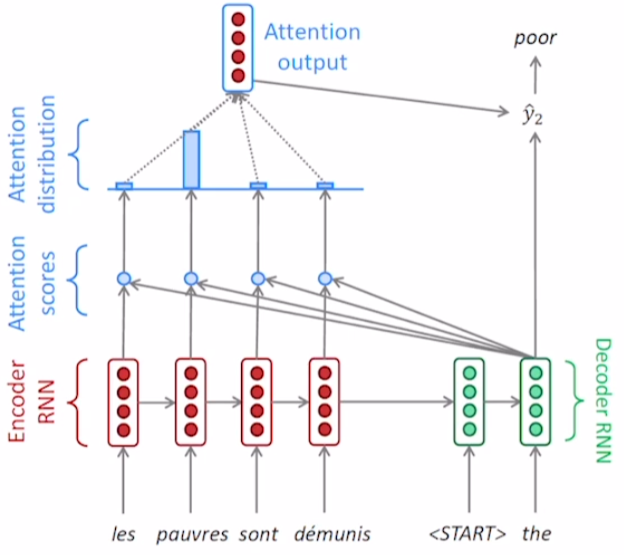
프랑스어 문장을 영어로 번역하는 task다.
encoder는 기존 Seq2Seq와 같이 각각의 step에서 hidden state가 발생한다. encoder의 마지막 step에서 발생하는 hidden state는 첫번째 decoder step의 입력 hidden state가 된다.
encoder의 hidden state들 중 어떤 것을 필요로 하는지 정하기 위해서, encoder의 $h_n^{(e)}$과 decoder의 $h_1^{(d)}$ 각각에 대해서 내적을 구한다. 즉, 위 그림에서는 4개의 내적 결과가 개별적으로 산출될 것이다. 내적 결과들은 hidden state들 간의 유사도로 생각할 수 있다.
내적 결과들에 logit처럼 생각해서 softmax를 적용하면 확률을 구할 수 있다. 구해진 확률들은 $h_n^{(e)}$에 부여되는 가중치로 사용된다.
** Attention vector ** 이렇게 생성된 합이 1인 가중치 vector를 attention vector라고 부른다.
가중치를 사용해 $h_n^{(e)}$들 간의 가중치가 적용된 평균을 구해서(가중평균) 하나의 attention output vecotr를 생성한다. 이러한 결과물을 context vector라고도 한다.
정리하면 decoder의 hidden state가 필요로 하는 정보들이 선택되서 새로운 encoder hidden state를의 결합물을 구한 것이다.
** Attention module ** 위 그림에서 초록선으로 묶은 부분을 attention module이라고 한다. 입력으로 encoder의 hidden state를 받고 출력으로 하나의 attention output을 연산하는 모듈이다.
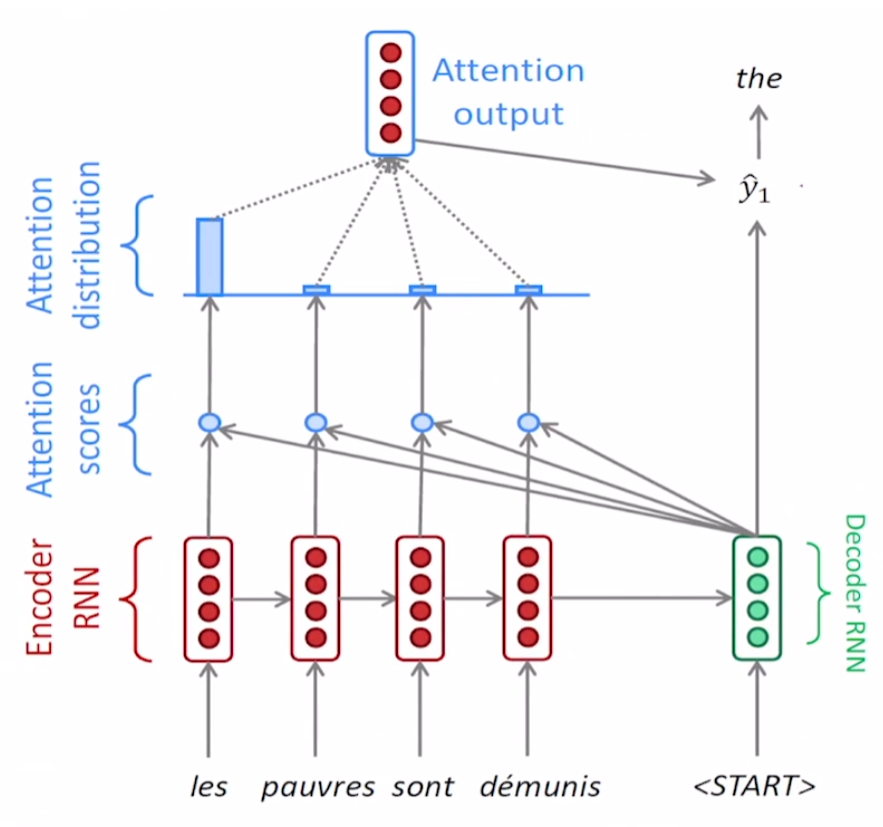
decoder의 hidden state과 context vecotr(attention ouput)이 concatenate가 되어 output layer의 input이 된다. 이렇게 다음 단어를 예측한다.
decoder의 2번째 step도 동일한 과정을 반복한다. decoder는 $h_1^{(d)}$를 입력 hidden state로 받고, ‘the’를 입력으로 받아 $h_2^{(d)}$를 출력한다.
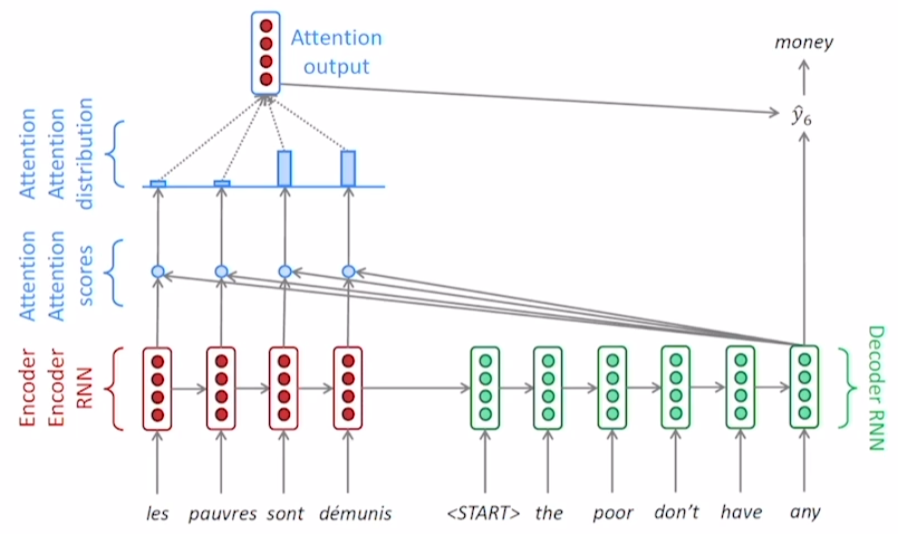
반복 작업은 출력으로 end token(EoS)가 나올 때까지 수행된다.
Decoder의 hidden state
decoder의 hidden state vector는 두 가지 역할을 해야 한다.
- encoder에서 어떤 hidden state를 중점적으로 가져올지 정해야한다.
- = attention vector를 만드는 정보를 가지고 있어야 한다.
- ouput layer에 input이 되어 결과를 예측하는데 사용된다.
decoder의 학습은 이 두가지 역할을 동시에 수행할 수 있도록 진행된다.
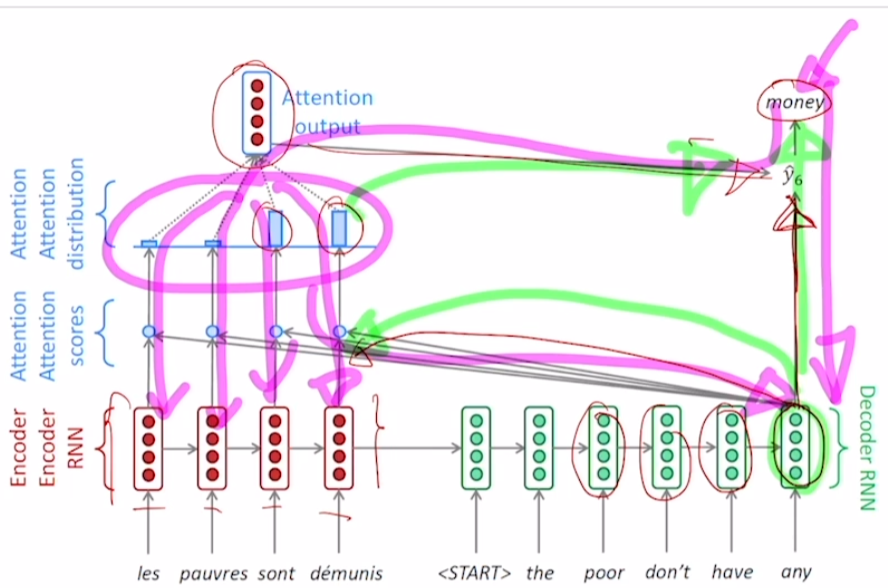
따라서 backpropagation은 위 그림의 보라색 선과 같은 경로로 진행된다.
Teacher forcing
Teacher forcing 방식에서 학습을 진행할 때 decoder 단의 입력은 ground truth가 된다. 즉, 학습을 진행하면서 모델이 다음 단어를 잘못 예측하더라도 ground truth를 통해 바로잡는 역할을 기대할 수 있다. 이러한 방식을 사용하면
유사도 측정
단순히 내적을 통해서 구할 수도 있지만 아래와 같이 여러 방법으로 유사도를 구할수도 있다.
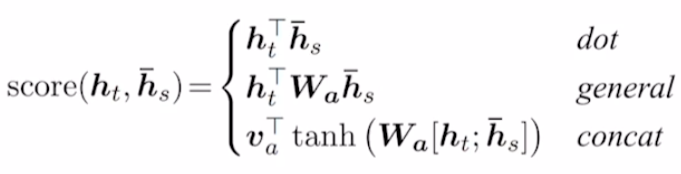
- $score$: 유사도를 구하는 함수
- $h_t$: decoder의 hidden state
- $\bar h_s$: encoder의 hidden state
$genral$ 내적을 수행할 때 $W_a$를 가중치로 두어 사용한다. 행렬의 곱셈에서 각각의 곱셈 요소에 가중치를 부여할 수 있는 권한을 준다고 생각하면 된다.
$\begin{pmatrix} a & b \ c & d \end{pmatrix}\begin{pmatrix} x & y \ z & v \end{pmatrix}$ 가령 위 식에서 행렬곱은 $ax+bz$, $ay+bv$ 등으로 구성된다.
이 때 하나 하나의 요소에 가중치를 부여해서 $w_0(ax+bz)$, $w_1(ay+bv)$과 같이 행렬곱 요소에 가중치를 조절할 수 있는 변수를 곱해주는 것이다. 딥러닝에서는 학습 시 조절 가능한 parameter가 발생한 것이다.
$concat$
$[h_t;\bar h_s]$에서 ;는 행렬간 concatenate를 의미한다. 수식을 보면 tanh로 묶인 항은 마치 neural netowrk와 동일한데 맞다!
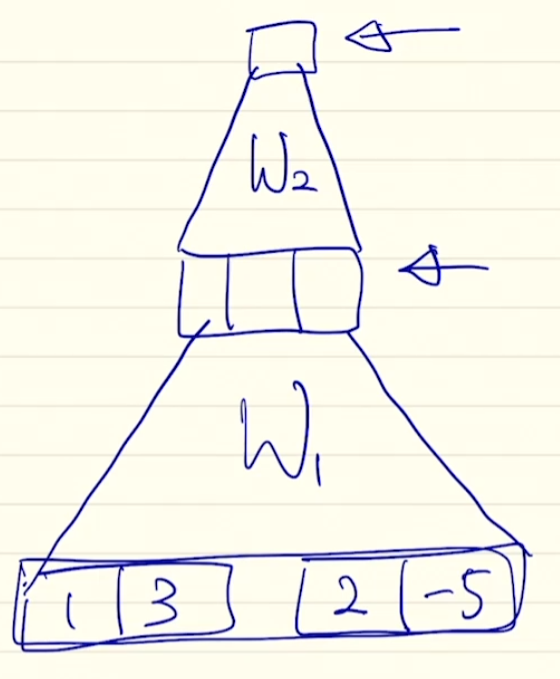
$h_t=[1,3]$. $\bar h_s=[2, -5]$라 하면 위와 같이 네트워크를 구성해보는 것이다. W1, W2는 fully connected로 구성된 네트워크를 의미한다.
그런데 수식을 보면 W2는 $v_a$로 표기된다. 이는 마지막 네트워크 단이 scalar로 나오기 위해서는 W2가 vector 형태가 되어야 하기 때문이다. 위 네트워크를 보면 3 dimension짜리 vector를 scalar로 만들기 위해서 W2 또한 3 dimension짜리 vector가 되어야 함을 알 수 있다.
유사도 측정의 방법을 다변화 하는 이유 모델 학습 시 단순히 내적을 하는 것에 비해서, 조절할 수 있는 parameter가 늘어난다. 또한 늘어난 parameter는 attention vector를 구하는 것에 크게 관여한다.
즉, 유사도 측정에 변수를 고려해서 모델이 atten vector를 구하는 과정 또한 학습할 수 있도록 유도할 수 있다.
Attention의 장점
- Mahcine translation의 성능을 정말 많이 올렸다.
- 이전의 Seq2Seq와 달리 decoder가 특정 정보에 집중할 수 있는 환경을 만들어줬다.
- 긴 문장이 제대로 번역되지 않던 문제를 해결.
- Attention sovles the bottleneck problem.
- 하나의 hidden state에 이전의 모든 정보를 담기 때문에 발생했던 문제들 해결.
- decoder가 소스의 정보를 바로 볼 수 있다!
- Attention solves gradient vanishing.
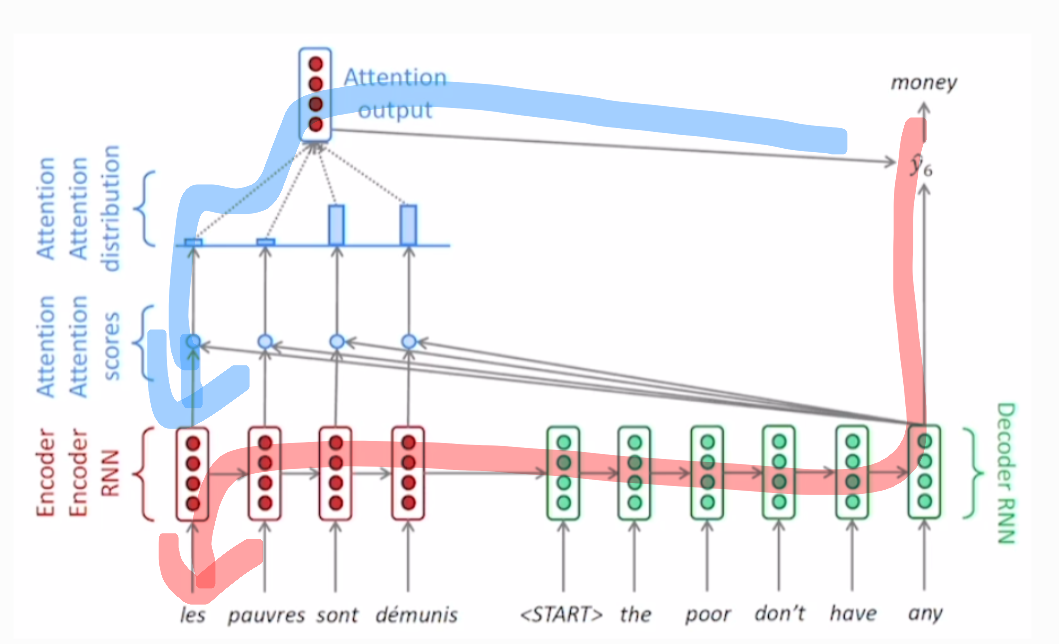
- 이전에는 decoder와 encoder를 통해서 순차적으로 backpropagation이 되며 loss가 전파됐다. (위 그림에서 빨간색 경로) 따라서 bottleneck 현상이 여기서도 발생한다. 특히나 encoder의 앞단에 위치한 step의 hidden state를 바꾸고 싶다면 backpropagation이 매우 깊게 발생해야 한다.
- attention을 사용하면 이러한 전파 과정이 간소화된다. (위 그림에서 파란색 경로). attention ouput을 통해서 마치 지름길과 같은 path가 backpropagation에서 발생한다.
- Atten provides some interpretability(해석능력).
- 특정 입력에 대한 attention vector의 분포를 알면, decoder가 어떤 정보에 focusing하는지 알 수 있다.
Attention 사례
 attention을 활용해 프랑스어를 영어로 번역한 사례이다. 순서대로 잘 번역하다가 어순이 뒤바뀌는 구절에 대해서는 atttention이 이러한 어순의 변화를 알아서 감지하고 알아서 번역해줬다.
end-to-end 방식으로 알아서 번역을 수행했다!
attention을 활용해 프랑스어를 영어로 번역한 사례이다. 순서대로 잘 번역하다가 어순이 뒤바뀌는 구절에 대해서는 atttention이 이러한 어순의 변화를 알아서 감지하고 알아서 번역해줬다.
end-to-end 방식으로 알아서 번역을 수행했다!
Leave a comment