
BLEU
일반적인 precision이나 recall을 계산하면 Seq2Seq에서는 모든 지표가 0에 가까울 것이다. 왜냐하면 step별로 비교하면 대부분 일치하지 않을 확률이 매우 높기 때문이다. 즉, 아래처럼 굉장히 유사한 문장의 지표가 0에 가깝게 나올 수도 있다.
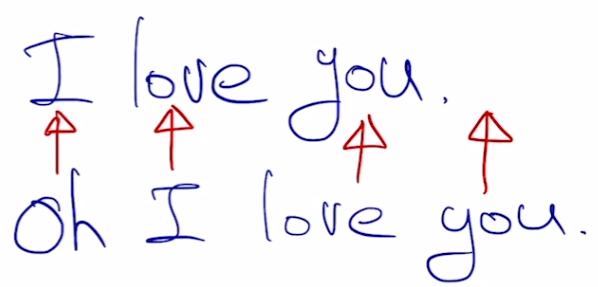
그래서 이러한 맥락을 지표에 반영할 필요가 있다.
Precision, RecallPermalink

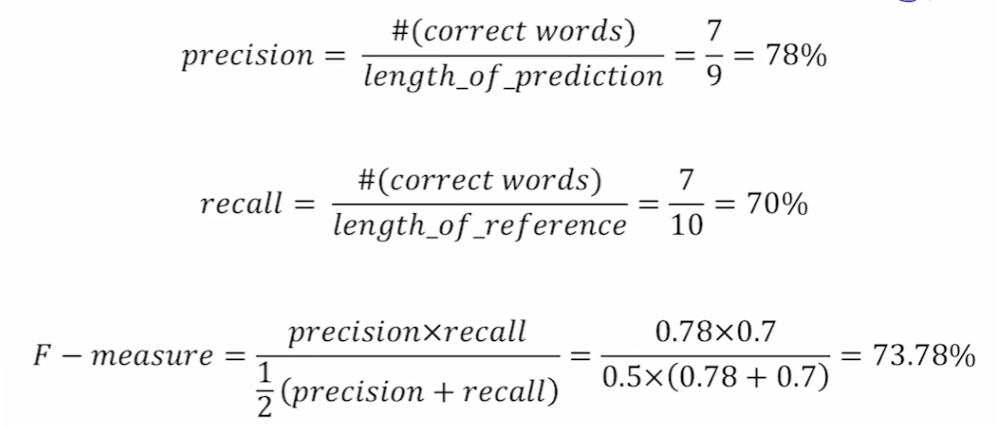
** Precision(정밀도) **
- 예측한 결과에 대해서 corrected words가 몇개인지 나타낸다.
- 예측한 결과를 기준으로 ground truth와 겹치는 단어 수
- 사용자에게 노출된 예측결과가 얼마나 정확한지 나타내는 지표.
- e.g., 사용자에게 노출된 검색결과들 중 제대로 찾은 검색 결과가 몇개인지
** Recall(재현율) **
- Ground truth에 대해서 corrected words가 몇개인지 나타낸다.
- Ground truth를 기준으로 예측한 결과와 겹치는 단어 수
- 실제로 찾아야하는 검색결과들 중에 검색엔진이 얼마나 찾아냈는지
- 사용자에게 노출되지 않은 정보들 중에서 사용자가 원하는 정보가 있을 수도 있다.
- 스타1의 리콜을 생각하면 편하다.
- 실제로 소환하고자 했던 유닛들 중에서 몇 개의 유닛이 소환됐는가?
F1 scorePermalink
Precision과 recall에 대한 통계량을 표현하고 싶다면 두 지표의 평균을 구하면 된다. 이 때 평균들의 대소 관계는 아래와 같다.
산술평균 >= 기하평균 >= 조화평균
F1 score는 조화평균을 사용하는데, Precision과 recall 중에서 보다 작은 지표에 집중한다. 내 생각에는 마치 Big O 표기법과 같이 최악의 상황을 가정하는 쪽으로 지향하는 것이 보다 정확한 지표이기 때문에 조화평균을 사용한 것 같다.
기계번역에서 기존 방식과 같이 f1 score를 연산하면 문법 고려, 어순 등 여러가지 요소들이 무시된다. 따라서 새로운 지표가 필요하다.
BLEU scorePermalink
BiLingual Evaluation Understudy. 블루라고 발음하시더라.
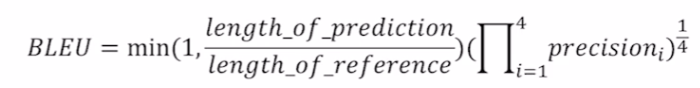
- 기존처럼 한개의 단어에 대한 overlap만을 계산하지 않고 N-gram overlap을 계산한다.
- 보통 1 ~ 4 gram 사용.
- 뒷 항에서는 Precision만 고려하고 recall은 고려하지 않는다.
- 기계번역에서 기존 문장을 빠짐없이 얼마나 재현했는가가 중요하지 않기 때문이다.
- 예측 결과가 기존 문장과 얼마나 겹치는가가 더 중요하다.
- 1 ~ 4 gram의 precision에 대한 기하평균을 계산한다.
- f1 score와 같이 지표들 중 작은 값에 치중하기 위함이다.
- 조화평균은 지나치게 작은 지표들에 가중치가 부여되기 때문에 사용하지 않는다.
Brevity penaltyPermalink
너무 작은 번역 결과에 대한 가중치를 계산하기 위한 항이다. BLEU 수식에서 min()에 해당한다.
예측한 결과가 기존 문장보다 짧다면 이 값이 1보다 작아진다.
이를 통해 뒷 항에서는 고려하지 못한 recall을 어느정도 고려해준다. 왜냐하면 재현률의 최댓값이 1보다 커지는 상황이 발생할 수 있는데 이를 최대 1로 억제시켜주기 때문이다. 또한 기존 문장보다 예측문장이 짧을 경우 이에 대한 수치를 곱해주는 역할 또한 한다.
Leave a comment