
RNNs
RNN
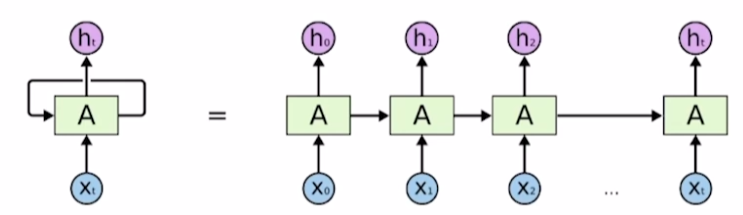
sequence data가 입출력으로 주어진 상태에서 t에서의 입력 $x_t$와 이전 hidden state인 $h_{t-1}$을 입력으로 받고 $h_t$를 출력하는 네트워크.
중요한 것은 매 time stamp마다 새로운 model이 등장하는 것이 아니라, 하나의 parameter set인 A가 모든 time stamp에 걸쳐서 사용된다.
왼쪽처럼 압축해서 표현한 것을 rolled diagram, 왼쪽처럼 time stamp를 표시한 것ㅇ unrolled diagram이다.
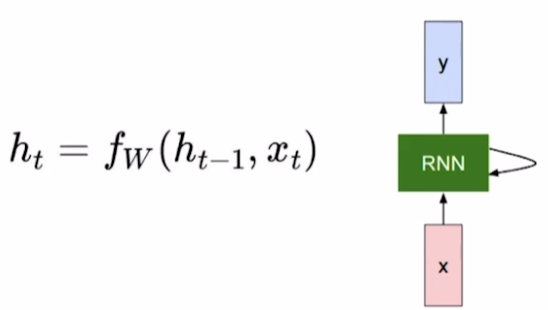
도식화하면 위와 같다.
- $h_t$: new hidden state vector
- $f_w$: RNN function with parameters W.
- W: linear transform matrix
- $y_t$: output vector at time step t.
- $h_t$를 활용해서 계산한다.
- time step마다 계산할 수도 있고, 마지막에 한번만 계산할 수도 있고 맘대로다.
- e.g., 품사 예측이라면 매 step마다 해야될 것이고, 문장의 긍정/부정을 판단하는 것이라면 마지막에 한번만 할 것이다.
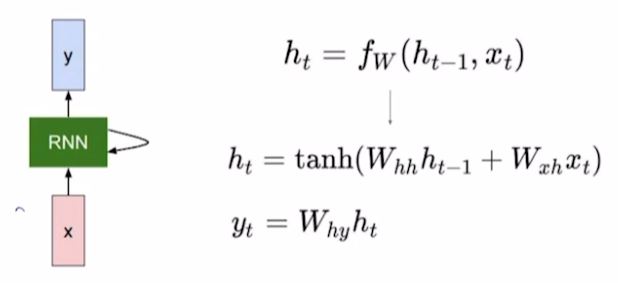
$f_w$는 위 수식처럼 non linear function으로 정의한다. 이 때, $W_{hh}$와 $W_{xh}$로 W를 분리해서 수식에서 적었는데 이는 아래 그림처럼 하나의 W matrix에서 유도된 것으로 생각해볼 수 있다.
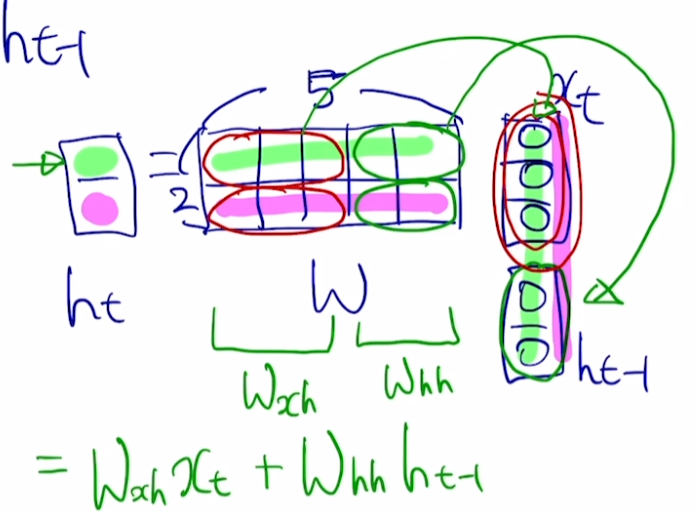
$h_t$의 차원은 hyperparamter이기 때문에 2로 정의해보자.
입력으로 $x_t$와 $h_{t-1}$을 받아서 $h_t$을 출력으로 내보내기 위해서 W는 (2, 5)의 크기를 가져야한다. 그래야만 $x_t$와 $h_{t-1}$의 concatenate 결과를 W와 내적했을 때 (2,1)이 나오기 때문이다. 이 때, 굳이 W를 (2, 5)로 하지않고 위 그림에서 빨간색과 초록색 동그라미로 분리된 부분으로 분리해볼 수 있다. 즉, $x_t$와 $h_{t-1}$가 각자의 W를 가지도록 한 후, 내적 결과를 더해주면 $h_t$가 알아서 생성된다는 것이다.
즉, $W_{hh}$는 $h_{t-1}$을 $h_t$로 변환해주고 $W_{xh}$는 $x_t$를 $h_t$로 변환해주는 역할을 한다.
같은 논리로 $W_{hy}$는 $h_t$를 $y_t$로 변환해주는 역할을 한다.
만약 binary classification이라면 $y_t$는 1차원 벡터, 즉 scalar 값을 가질 것이다. 여기에 sigmoid를 씌워서 결과값을 예측되는 확률로 사용할 것이다. Multi class라면 class의 개수가 $y_t$의 dimension일 것이고 추가적으로 softmax를 사용해서 확률분포를 얻는다.
Type of RNN
RNN은 입출력 중 한 가지가 sequence이거나 모두 sequence data인 경우를 통합적으로 다룰 수 있다.
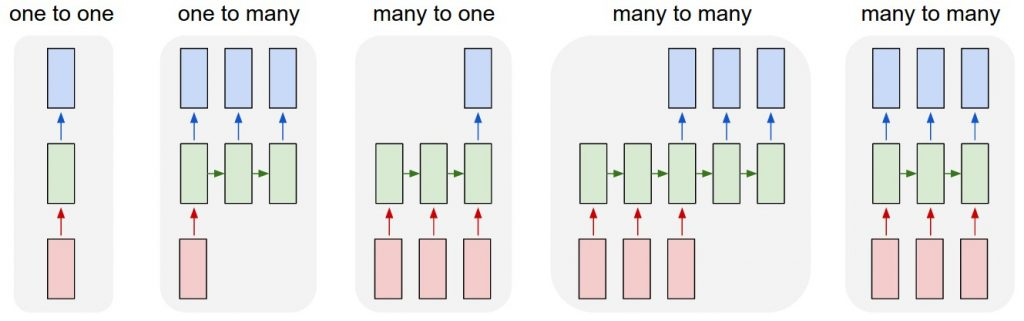 ref: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
ref: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- one to one(standrad neural network)
- 입출력 모두 sequence data가 아니고, time step도 하나인 형태다.
- 일반적으로 알고 있는 DNN과 동일한 구조다.
- one to many
- 입력은 sequence data가 아니지만, 여러 time step에 걸쳐서 sequence data를 출력한다.
- 처음에만 실제로 입력이 발생하기 때문에, 나머지 time step에서는 모든 값이 0인 tensor를 입력으로 준다.
- e.g., Image captioning
- many to one
- 매 time step에 맞춰서 입력이 발생하고 마지막에 한 번의 출력이 발생.
- e.g., Sentiment classification(감정 분석)
- many to many
- sequence data를 time step별로 입력한 후에 time step 별로 sequence data를 출력한다.
- e.g., Mahcine translation
- 모든 time step마다 입력, 출력 발생
- e.g., Video classification on frame level
- sequence data를 time step별로 입력한 후에 time step 별로 sequence data를 출력한다.
Character-level language model
language model(언어 모델)은 주어진 문자열, 단어들의 순서를 바탕으로 다음 단어가 무엇인지 맞추는 task. word, character level에서 모두 수행 가능하다.
Character-level language model의 구축은 다음과 같은 순서로 진행된다.
Exmaple of training sequence: “hello”
- Character 단위로 unique vocabulary를 만든다. [h, e, l, o]
- vocabulary의 character들은 word embedding에서 했던 것처럼 one-hot vector로 표현한다. h = [1,0,0,0]
- 아래 수식에 맞게 “hell”을 순서대로 RNN에 넣어서 계산한다.
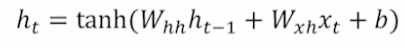
중요한 점은 매 time step마다 다음 character를 예측해줘야 하는 task라는 것이다. 즉, many to many의 형태로 RNN을 구성해야 한다. 이는 아래 그림과 같다.
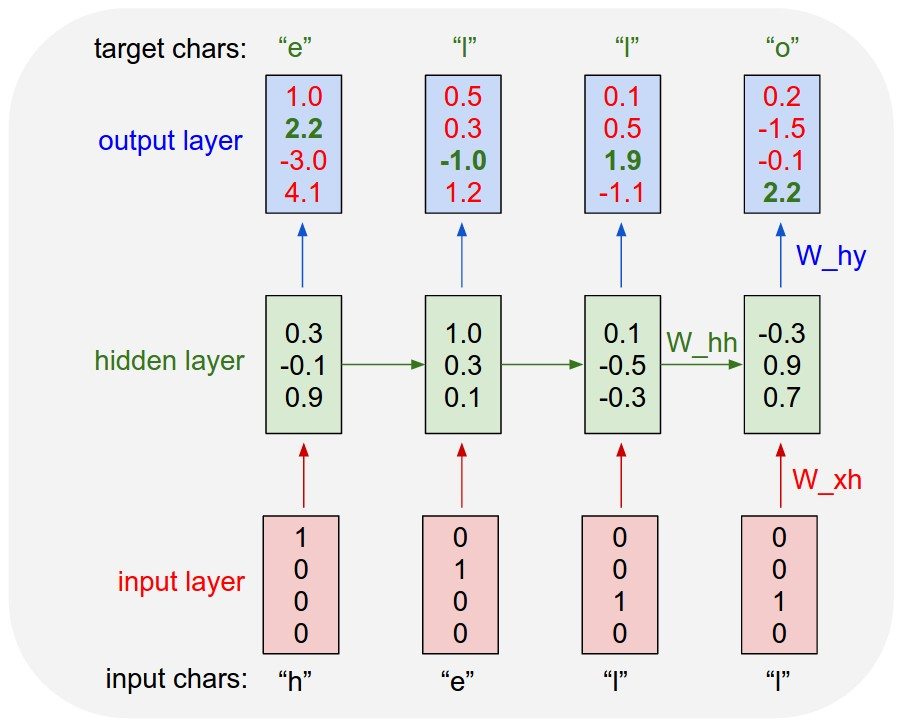
output은 아래 수식과 같이 계산할 수 있다.
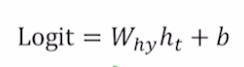
logit이라고 쓰는 이유는 multi class classification을 위해서 softmax를 사용하기 때문이다.
Inference
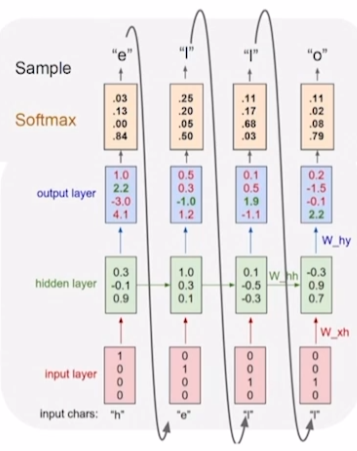
RNN이기 때문에 매 time step의 출력을 다시 다음 time step의 입력으로 사용할 수 있다. 즉, 첫번째 character인 ‘h’만 입력으로 주고 나머지는 알아서 출력하게 한다.
Training Shakespeare’s plays
 character 단위에서 사용했던 방법론을 글에서도 사용할 수 있다.
단어 단위로 Vocabulary를 만들되, punctuation도 모두 vocabulary에 포함시킨다. 쉼표,’\n’, 공백 등 모두 포함시킨다. 이렇게 해서 rnn으로 간단한 language model을 구성해볼 수 있다.
character 단위에서 사용했던 방법론을 글에서도 사용할 수 있다.
단어 단위로 Vocabulary를 만들되, punctuation도 모두 vocabulary에 포함시킨다. 쉼표,’\n’, 공백 등 모두 포함시킨다. 이렇게 해서 rnn으로 간단한 language model을 구성해볼 수 있다.

학습을 진행하면 할 수록, 첫번째 character를 주어졌을 때 완성되는 나머지 문장들이 더욱 자연스러워진다.
다른 예제들
- 희곡에서 인물과 대사를 구분해서 학습할 수 있다.
- LaTeX로 쓰여진 논문을 학습해서 새로운 논문을 inference할 수 있다.
- C언어를 학습해서 코드를 생성할 수 있다.
BPTT(Backpropagation through time)
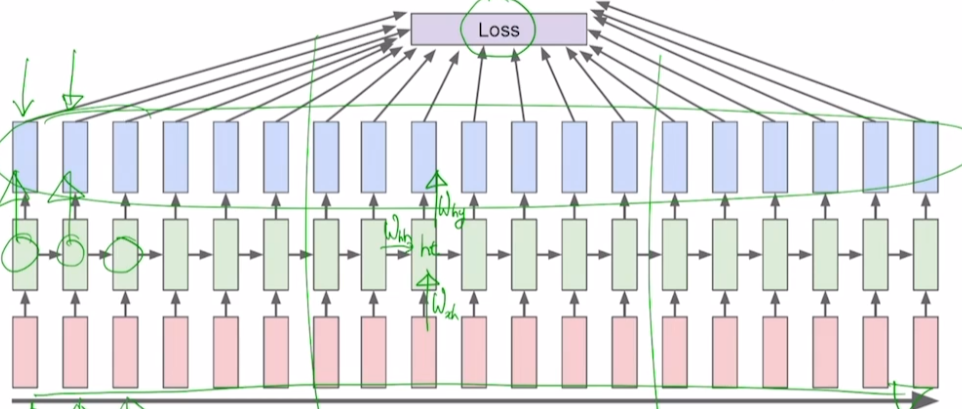 모든 loss를 활용해서 학습한다면 좋겠지만, 보통 sequence의 길이가 매우 길어서 모든 loss를 활용할 수 없다. 따라서, 학습에는 모든 데이터를 사용하되 loss는 일부 구간에서만 가져와서 Backpropagation을 한다.
모든 loss를 활용해서 학습한다면 좋겠지만, 보통 sequence의 길이가 매우 길어서 모든 loss를 활용할 수 없다. 따라서, 학습에는 모든 데이터를 사용하되 loss는 일부 구간에서만 가져와서 Backpropagation을 한다.
How RNN works
RNN이 어떻게 학습을 진행하는지 추적해볼 수 있다. hidden state에 t 시점 이전의 정보들에 대한 모든 정보들이 담겨 있다. 즉, hidden state가 초기에 비해서 어떻게 변화하는지 추적해본다면 RNN이 어떻게 학습하는지 알 수 있다.
아래 결과들은 Vanila RNN은 아니고 LSTM, GRU를 사용했을 때의 hidden state 변화를 나타낸 것이다.
빨간색은 hidden state의 특정 셀이 음수로 커지는 것이고, 파란색은 양수로 커지는 것을 나타낸다.
 Quote Detection을 담당하는 cell을 hidden state에서 추적해보니 위와 같은 결과가 나왔다.
Quote Detection을 담당하는 cell을 hidden state에서 추적해보니 위와 같은 결과가 나왔다.
 if statement를 담당하는 cell의 hidden state는 위와 같이 변화했다.
if statement를 담당하는 cell의 hidden state는 위와 같이 변화했다.
Vanishing/Exploding gradient in RNN
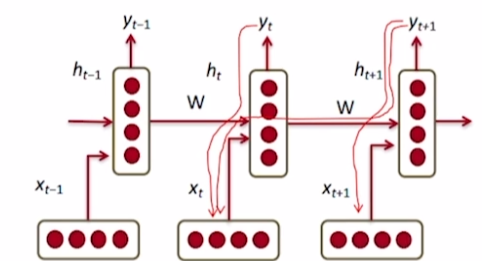
RNN 자체는 훌륭하나 backprogation에서 문제가 발생한다. RNN은 $W_h$를 지속적으로 곱하고 activation function을 통과시킨 형태로 수식이 짜여진다. $W_h$이 반복적으로 곱해지는 형태는 backpropataion에서 gradient 값이 1보다 크다면 매우 커지거나 1보다 작다면 매우 작아지는 현상을 초래한다.

간단하게 이해하기 위해 W를 scalar로 생각해서 예시를 들면 위와 같다.
backpropagation에서 gradient를 구하기 위해 h3를 미분한다. 이 때, h1에 대한 gradient를 구하기 위해서는 합성함수의 미분을 3번이나 풀어줘야하는데 이 때 $w_{hh}$인 3이 3번이나 곱해지면서 gradient가 된다. h3이 아니라 더 커다란 seuquence였다면 gradient는 더 큰 3의 거듭제곱에 비례할 것이다. $w_{hh}$이 1보다 작은 값이었다면 값은 매우 작아지는 형태로 나타날 것이다.
결과적으로 h3에서 발생한 값을 h1까지 잘 전달할 수 있는 형태가 되야하는데, 그렇지 못하고 되려 무한대나 0으로 gradient가 수렴하는 것이다.
Leave a comment