
Word Embedding
Word Embedding
문장의 단어들을 벡터 공간 상의 점으로 표현하기 위해, 단어들을 벡터로 변환하는 방법.
Word Embedding 자체가 딥러닝, 머신러닝 기술이다. 학습 데이터, 사전에 정의한 벡터 공간의 차원 수를 통해 학습을 진행한다. 학습이 완료되면 학습 데이터, 즉 특정 단어에 대한 최적의 벡터를 출력해준다.
Word Embedding의 기본 아이디어
비슷한 의미를 가지는 단어들이 벡터 공간에서 비슷한 위치에 맵핑되게 하여 유사도를 가지게 한다. 이를 통해 다른 자연어 처리에서 더욱 쉽게 task를 처리하도록 환경을 제공한다.
Word2Vec
Word Embedding의 대표적인 예시이다.
하나의 문장에서 인접한 단어들은 비슷한 의미를 가질 것이라는 가정이 이 알고리즘의 기본 아이디어다. 즉, _특정 단어는 주변의 단어들을 통해 해당 단어의 의미를 알 수 있다_는 논리가 존재하는 알고리즘이다.
The cat purrs. This cat hunts mice.
위 두 문장에서 cat 주변에는 The, purrs, this, hunts, mice가 있다. 그렇다면 이 단어들은 cat과 유사한 의미를 가질 것이라는 가정이 존재하는 것이다.
예측 방법
학습데이터를 바탕으로 target 단어(여기서는 cat) 주변 단어들(w)의 확률 분포를 예측한다.
 만약 cat이 입력으로 주어졌다면, 주변 단어를 숨기고 $P(w|cat)$의 학습을 진행한다.
만약 cat이 입력으로 주어졌다면, 주변 단어를 숨기고 $P(w|cat)$의 학습을 진행한다.
학습 방법
- 주어진 문장을 word로 분리하는 Tokenization을 수행.
- Unique words로 vocabulary 구축.
- Vocabulary의 각 단어들은 Vocabulary의 사이즈만큼의 dimension을 가지는 One-hot vector로 나타낸다.
- Sliding windows를 통해 학습 데이터의 입출력 쌍을 구성한다.
가령 Sliding windows의 크기가 3이라고 해보자.
I study math.
해당 문장에서 I에 Sliding windows를 적용한다면, I를 기준으로 앞뒤로 1개의 단어들을 살펴본다. 앞에는 아무 단어가 없고, 뒤에 study가 있으므로 I를 기준으로는 (I, study)라는 입출력 쌍이 구성된다.
study를 기준으로 한다면 앞뒤로 I와 math가 있다. 그러므로 (study, I), (study, math)라는 입출력 쌍이 구성된다.
- 간단한 neural network를 구성해서 준비된 쌍들을 학습한다.
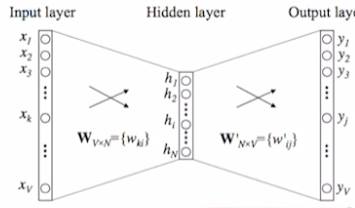
Input Layer: 입력 one-hot vecotor의 차원 수만큼의 node를 가진다. Output Layer: 출력 one-hot vecotor의 차원 수만큼의 node를 가진다. Hiddne Layer: Word embedding을 수행하는 좌표 공간의 차원수와 동일하게 node를 구성. 사용자가 설정하는 hyperparameter.
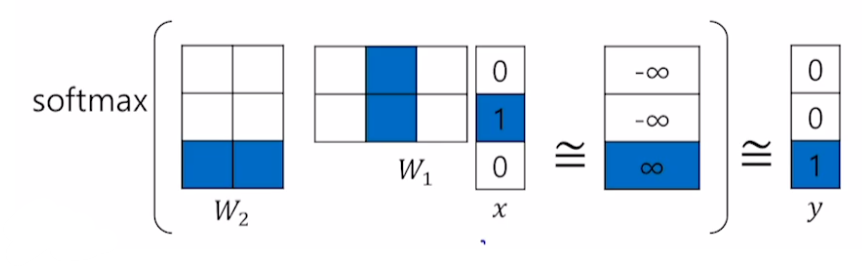
위 neural network를 벡터로 도식화하면 위와 같다.
$W_2(W_1x)$의 형태로 곱할 것이기 때문에 W1은 (2,3,), W2는 (3,2)로 구성한다. 그 후 softmax를 통과시켜서 3차원 벡터가 확률분포를 가지도록 바꿔준다. 이렇게 구한 출력 값과 y 벡터 간의 거리가 가장 가까워지도록 neural network를 학습하기 위해 softmax loss를 사용한다.
내적 계산
일반적인 행렬곱을 계산해도 되지만 one-hot vector의 특성 상, 한 개 성분만이 1을 가지기 때문에 특정 index의 값만 취하게 된다.
예를 들면 위 그림에서 W1와 x를 곱할 때, x의 2번째 성분만이 1이기 때문에 W1에서 2번째 column만을 취하게 된다.
이러한 성질을 활용해서, one-hot vector를 곱할 때는 행렬곱을 수행하지 않고 특정 index의 값만을 취하는 형태로 연산이 발생한다.
W2는 Vocabulary의 수만큼 row vector를 가질 것이다. 실제로 3개의 row를 가지고 있다. row의 차원은 W1과 내적이 가능하도록 2가 될 것이다.
Ground truth 실제 값을 의미한다. 기상학에서 쓰이던 용어인데, 인공위성과 같이 멀리석 관측한 데이터가 아니라 실제 지상에서 관측한 값을 지칭할 때 쓰던 용어다. 기계 학습에서는 y hat이 아니라 학습 데이터로 주어지는 실제 y 값이라고 생각하면 된다.
logits sigmoid와 역함수 관계에 있는 함수. 출력이 −∞ ~ +∞다. ref: https://velog.io/@gwkoo/logit-sigmoid-softmax%EC%9D%98-%EA%B4%80%EA%B3%84
$W_2(W_1x)$의 값이 ground truth와 일치하게 하려면 ground truth가 1인 3번째 index에서 logits 값이 무한대고 나머지에서는 logits 값이 -무한대여야할 것이다.
이해 못 한 점
W1와 W2에 대한 연산이 벡터 간의 유사도를 측정하는 것과 같다고도 하셨는데 무슨 말인지 모르겠다..
Property of Word2Vec
Word2Vect는 단어들간의 의미론적 관계를 vector들 간의 관계에 잘 학습해준다.
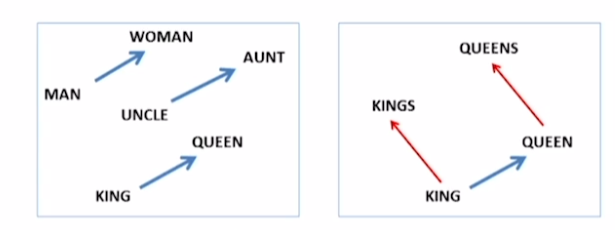
위 그림은 Word2Vec을 통해 학습된 단어들의 vector다. 서로 비슷한 관계에 있는 벡터들 간의 관계(벡터들 간의 차이)는 같은 방향성을 가지는 것을 알 수 있다.
Word2Vec 한글
https://word2vec.kr/search/?query=%ED%95%9C%EA%B5%AD-%EC%84%9C%EC%9A%B8%2B%EB%8F%84%EC%BF%84
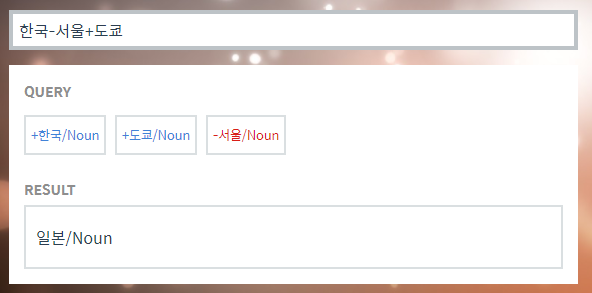
Word2Vec을 한글에서 구현한 예제이다. 쿼리문은 다음과 같이 사용된다. 한국-서울은 나라와 수도 간의 관계를 나타내도록 해준다. 그리고 이것에 도쿄를 더하면 나라와 수도 간의 관계를 도쿄에 적용시켜주고 그에 대한 결과를 보여준다.
Intrusion Detection
여러 단어가 주어졌을 때, 나머지 단어와 가장 의미가 상이한 단어를 찾는 task. Word2Vec을 통해 Word Embedding 결과를 구해서 해결할 수 있다.
특정 단어에 대한 나머지 단어들의 Euclidian distance를 구하고 평균을 낸다. 이러한 과정을 모든 단어에 대해 반복하고 거리의 평균이 가장 큰 단어를 구하면 된다.
Application of Word2Vec
본래 단어의 의미를 찾기 위한 방법론이지만, Word Embedding 결과를 쉽게 뽑아주는 task이다. 따라서 단어를 벡터로 변환해야 되는 다른 nlp 방법론에서도 유용하게 많이 사용한다.
- Word simliarity
- Machine translation
- 서로 다른 언어에서 같은 의미를 가지는 단어들이 쉽게 align될 수 있게 해준다.
- PoS tagging
- NER
- Sentiment analysis
- 단어들의 긍정, 부정을 쉽게 표현할 수 있게 해준다.
- Clustering
- Semnatic lexicon building
- Image captioning
GloVe
Word2Vec과 함께 많이 사용되는 Word Embedding 방법론.
Word2Vec과의 가장 큰 차이점은, 학습 데이터 내에서 한 단어 쌍이 하나의 windows에서 동시에 출현한 빈도 수를 미리 모두 계산한다. 이것을 $P_{ij}$라고 하자.
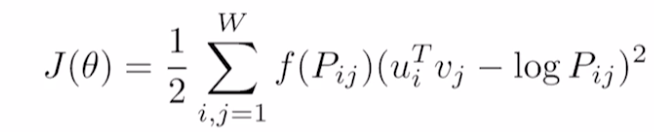
GloVe의 object(loss) function은 위와 같다.
- $u_i$ = input word embedding vector
- $v_j$ = output word embedding vector
- $P_{ij}$ = i, j 두 단어가 한 window 내에서 동시에 몇 번 존재하는가.
선형대수적인 관점에서, 추천시스템 알고리즘인 co-occurrence low rank matrix factorization로도 이해할 수 있다.
장점
중복되는 계산을 줄일 수 있다. 가령, study와 math가 동시에 많이 존재한다면 Word2Vec은 두 단어 간의 관계에 대해 그냥 많이 학습한다. 하지만 GloVe는 미리 두 단어의 동시 존재성에 대해서 알고 있다.
따라서 위 수식에서 study와 math의 경우 내적 값에 큰 값을 빼주면서 학습을 더 빨리 할 수 있게 해준다.
또한 더 적은 데이터에 대해서도 잘 작동한다.
예시
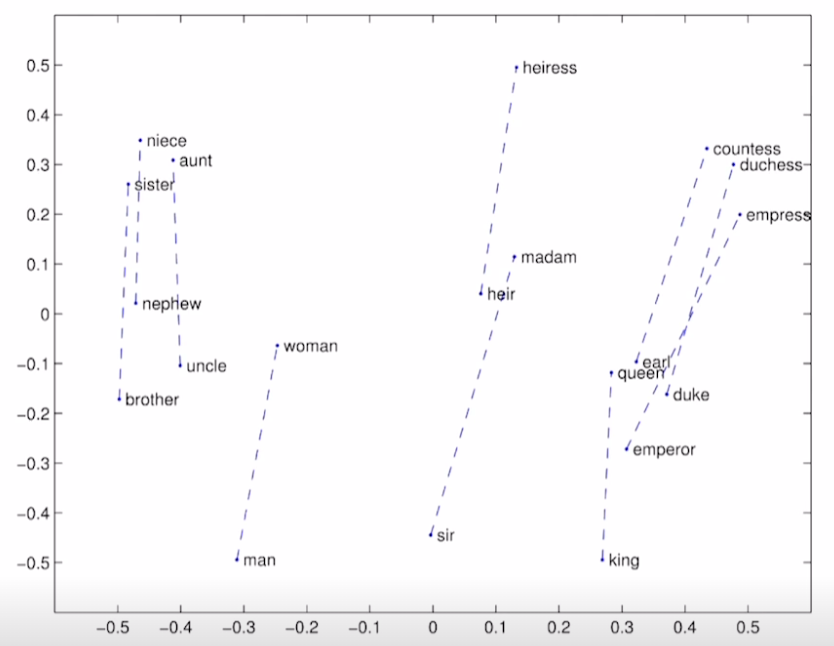
성별만 다르고 의미가 같은 단어에 대해 GloVe를 수행한 결괄르 PCA로 찍어본 결과다. 성별의 차이가 일정한 크기와 방향을 가진다는 것을 알 수 있다.
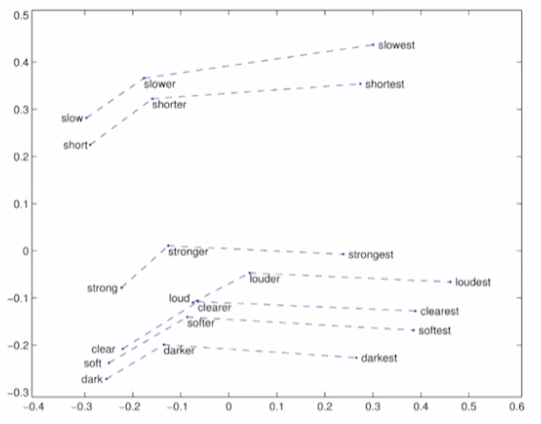
형용사의 comparative, superlative 또한 크기와 방향성을 학습한다!
Pre trained model
https://nlp.stanford.edu/projects/glove/
wikipedia, crawling, twitter에서 수집한 단어들에 대한 pre trained 모델을 배포해준다.

- uncased: 대소문자가 구별된 단어라도 같은 단어로 취급
- cased: 대소문자가 구별된 단어를 다른 단어로 취급
- dimesion: 입출력 word 벡터의 dimension
Leave a comment