
문장 토큰 분류
모델
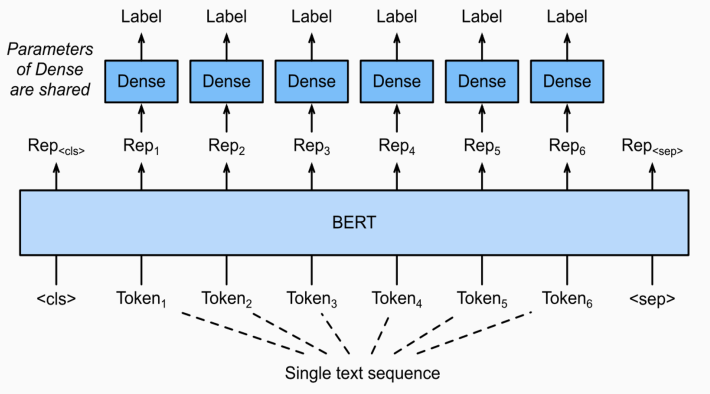
주어진 문장의 각 token들이 어떤 범주에 속하는 분류하는 task. classifier가 token마다 붙게된다.
NER
Named Entity Recognition. 문맥을 통해 문서에서 인명, 기관명 같은 특정 의미를 가진 단어 / 어구 / 개체를 인식하는 과정.
같은 단어라도 다양한 Entity로 인식될 수 있기 때문에 문맥을 파악하는 것이 중요하다.
https://github.com/kakaobrain/pororo
카카오에서 개발한 NLP, Speech-related task library다. 한국어로 처리 가능한 대부분의 task를 수행해주는 라이브러리인데, NER 또한 포함돼있다.
POS Tagging
Part-of-speech tagging.
- 문서를 품사, 형태소로 분리
한국어 데이터
- kor_ner
- 한국어해양대학교에서 발표한 NER 데이터셋
- NER 데이터셋은 보통 pos tagging 정보도 포함돼있고 kor_ner도 포함돼있다.
- BIO tag로 라벨링 wikidocs

학습
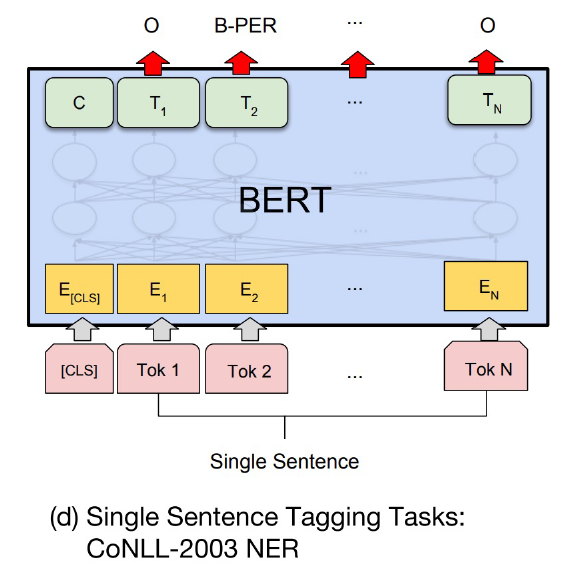
앞서 설명한 것처럼 token별로 classifier를 부착해서 학습을 수행한다.
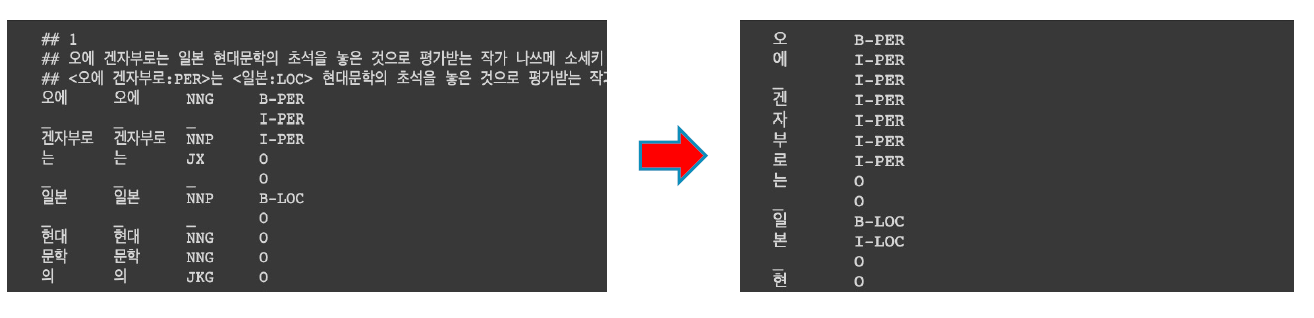
** 문장 토큰 분류 시, 음절 단위의 tokenizing 추천! ** 형태소, 어절 단위로 분류하게 되면 Entity의 정의 자체가 모호해지는 경우가 있기 때문이다. 가령, ‘이순신은’을 ‘이순’과 ‘신은’으로 분류할 수도 있는데 ‘신은’은 아무리 학습을 해도 사람으로 분류하기 쉽지 않다.
Leave a comment