
Dense Embedding
Sparse Embedding의 문제점
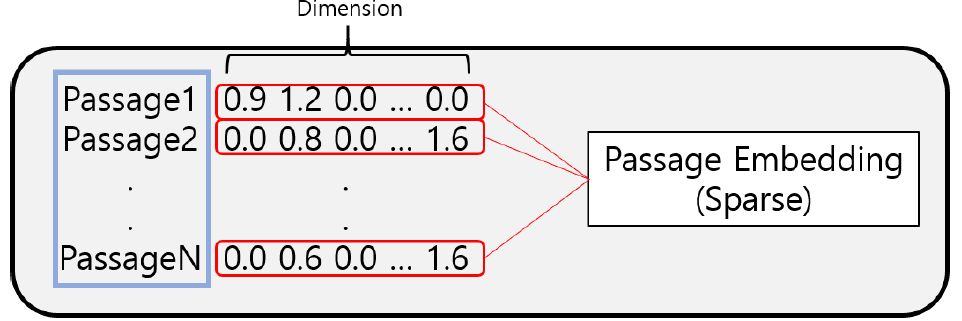
- Passage Embedding 중 Spare Embedding은 보통 90% 이상의 벡터값들이 0이다.
- 차원의 수가 매우 크다.
- compressed format으로 극복 가능
- 유사성을 고려하지 못한다.
- 매우 유사한 단어라도, character가 달라지면 전혀 다른 차원으로 Embedding 된다. 또한 유사한 단어들의 차원이 유사하다는 정보를 표현할 방법이 없다.
Dense Embedding

- 매우 유사한 단어라도, character가 달라지면 전혀 다른 차원으로 Embedding 된다. 또한 유사한 단어들의 차원이 유사하다는 정보를 표현할 방법이 없다.
- 고밀도로 vocab과 차원이 mapping
- 보통 50 ~ 1000 차원
- 모든 차원의 정보를 조합해 얻은 위치가 term의 위치가 된다.
- BoW처럼 하나의 차원이 하나의 term을 나타내지 않는다.
- 대부분의 요소가 non-zero이다. = 의미가 있다.
- dimesion이 BoW에 비해 매우 작기 때문에 더 많은 종류의 알고리즘 활용 가능
Sparse Embedding과의 차이점
- Sparse Embedding
- 정확히 일치하는 term을 찾고자 할 때 성능이 뛰어남
- Embedding이 구축되면 추가 학습 불가능
- Dense Embedding
- 단어의 유사성, 맥락 파악에서 성능이 뛰어남.
- 학습을 통해 Embedding 생성, 추가 학습 가능.
보통 Sparse Embedding만을 쓰는 경우는 거의 없다. 보통 Dense Embedding만을 쓰거나 두가지를 함께 사용해서 Retrieval을 수행.
Overview of Passage Retrieval with Dense Embedding
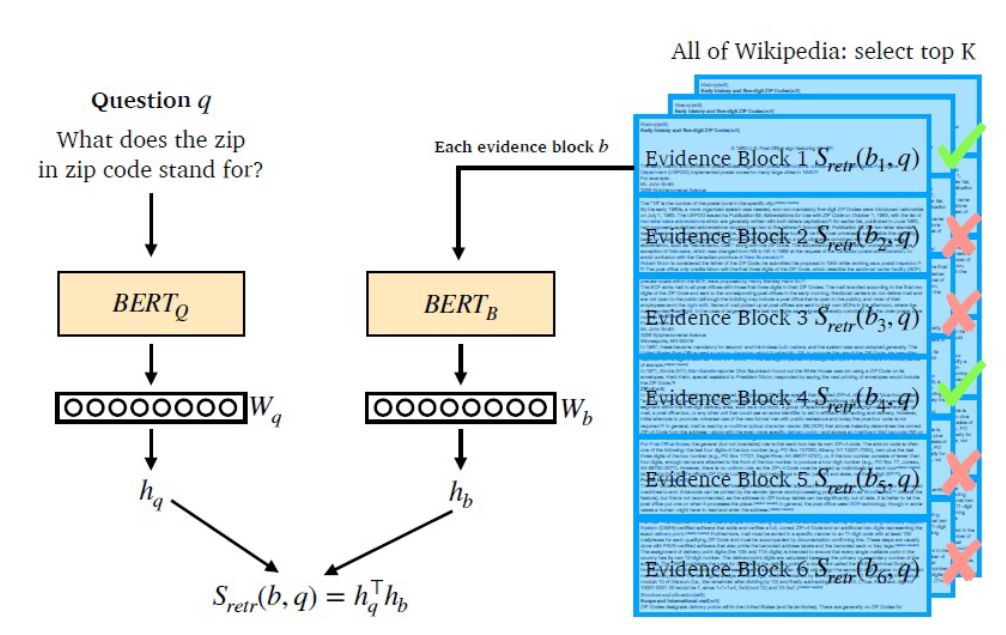 query에 대한 hiddens state(CLS 값)을 추출한다. 각각의 passage에 대해서도 동일하게 hidden state를 뽑는다. 이렇게 추출한 두 hidden state의 diemension이 일치한다는 가정 하에, inner product로 유사도를 구한다.
query에 대한 hiddens state(CLS 값)을 추출한다. 각각의 passage에 대해서도 동일하게 hidden state를 뽑는다. 이렇게 추출한 두 hidden state의 diemension이 일치한다는 가정 하에, inner product로 유사도를 구한다.
- \(BERT_Q, BERT_B\)는 동일한 모델을 쓸 수도 있고 다르게 미리 학습해두고 사용할 수도 있다. Task에 적합하게 구성하자.
Training Dense Encoder
예제는 BERT지만 뭐든 상관없다. PLM(Pre-trained language model)이기만 하면 된다.
- MRC model: 하나의 PLM에 query, answer를 함께 넣어준다.
- Dense Encoder: Query, passage 별로 서로 다른 PLM을 준비하고 각각의 PLM에 query와 passage를 넣는다.
- 서로 다른 CLS token의 최종 output을 활용하기 위해서다!
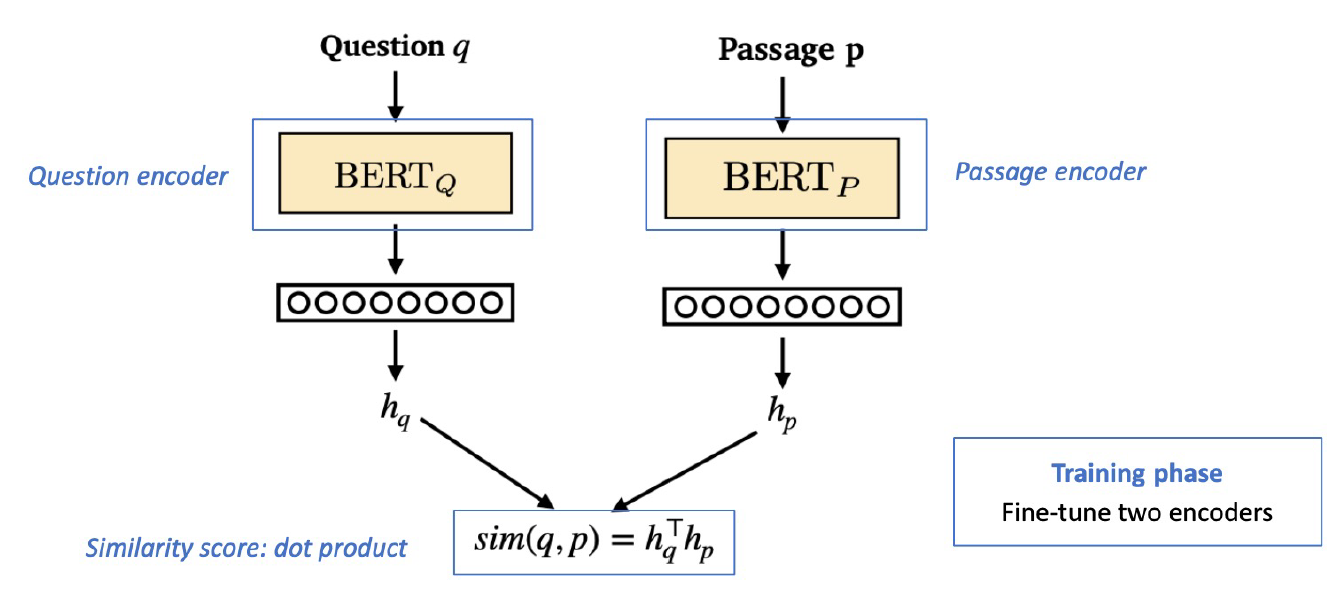
앞서 언급했듯 Question encoder, Passage encoder는 동일한 것을 사용해도 무방하고 서로 다르게 Fine-tuned 후 사용해도 된다.
Training goal
question과 passage dense embedding 사이의 거리를 좁히는 것. = inner product 값을 높이는 것 = higher similiarity를 찾는 것.
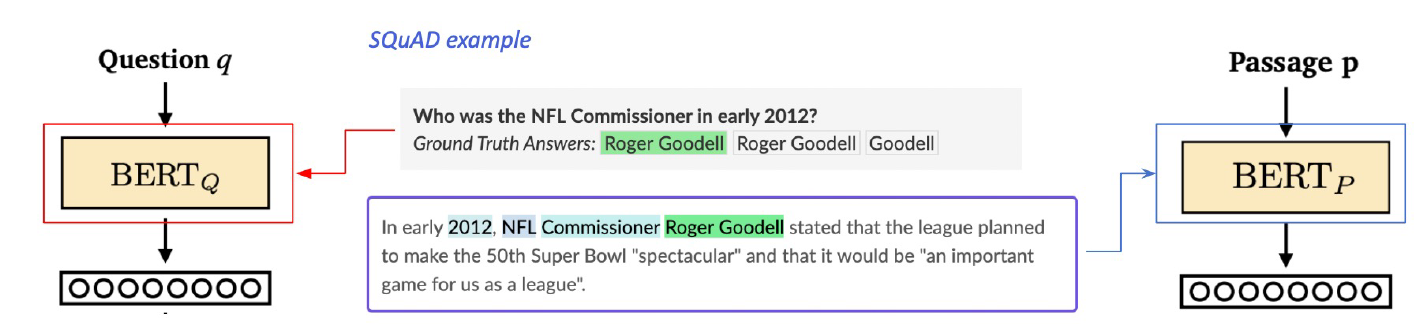
How to train?
- 기존 MRC dataset의 context와 answer를 활용한다.
- e.g., SQuAD
- 서로 연관된 question, passage는 dense embedding 거리를 좁혀준다.
- high similiarity, positive
- MRC Dataset에서 실제 context, answer를 그대로 사용한다.
- 서로 연관되지 않은 question, passage는 dense embedding 거리를 멀게 해준다.
- MRC Dataset에서 answer에 대한 임의의 context를 사용한다.
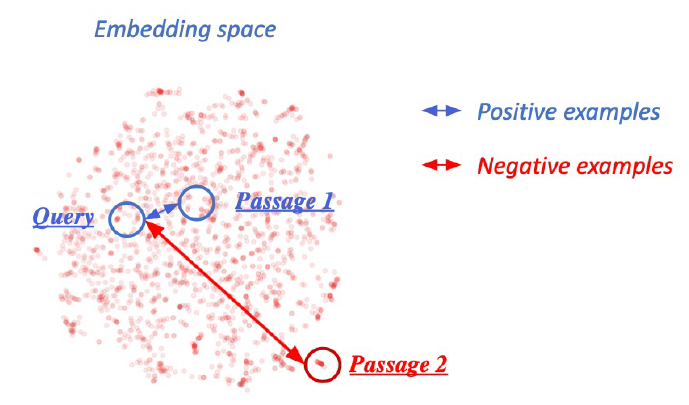
- MRC Dataset에서 answer에 대한 임의의 context를 사용한다.
Choosing negative samples
- corpus 내에서 random 추출
- 모델이 헷갈리도록 추출
- 높은 TF-IDF 값을 가지지만 답을 포함하고 있지 않은 sample
Objective function
Positivie passage에 대한 negative log likelihood(NLL) loss 사용

목표: Postive passge의 score를 확률화
- positive passage와 question의 simliarity score
- negative sample에 대한 score 두 score를 가져와 softmax를 취하고 negative log likelihood를 취해서 학습한다.
위 수식은 negative log likelihood를 표현한 것이다. negative log니까 -log가 붙고 log 안에는 softmax를 넣어준다.
corpus를 question, positive, negative로 나눴는데 softmax의 분자에는 positive 요소가, 분모에는 negative 요소까지 포함되서 표현됐다. softmax의 정의가 (target / 전체) 이기 때문이다.
Evaluation Metric
- Retrieval passage 중에서 ground truth passage가 포함됐는지 확인
- Retrieval passage 중에서 답을 포함하는 비율을 확인
- extractive-base mrc라면 passage에 답이 없으면 답을 낼 수 없다.
- 따라서 upper bound 형태.
Passage Retrieavl with Dense Encoder
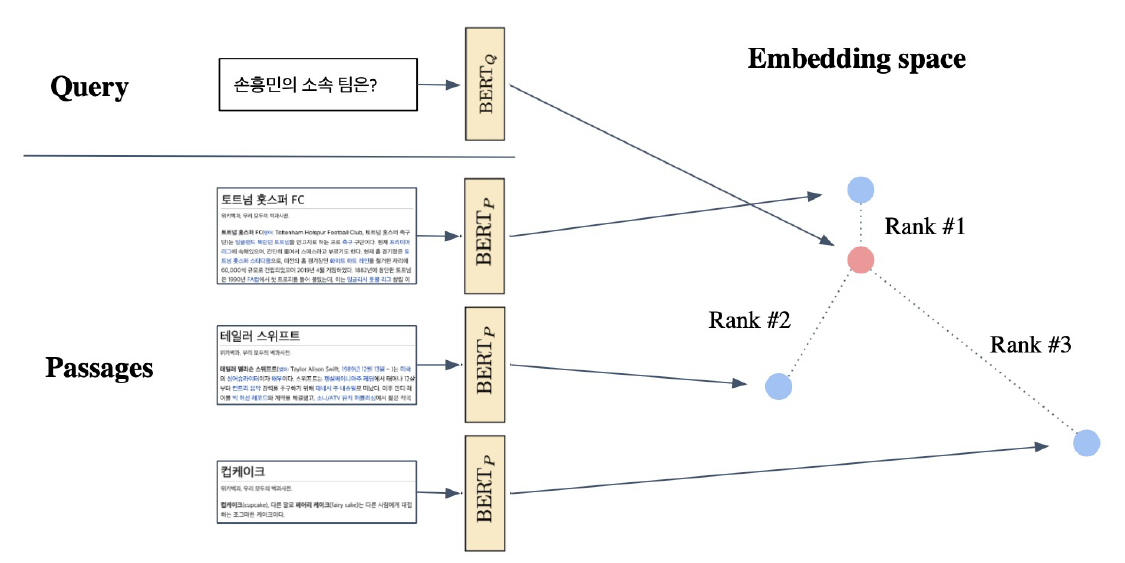
Overview에서 보여줬던 내용이다. 미리 계산된 passage들의 embedding 값을 query embedding과 거리 비교를 해서 가장 가까운 passage를 고른다.
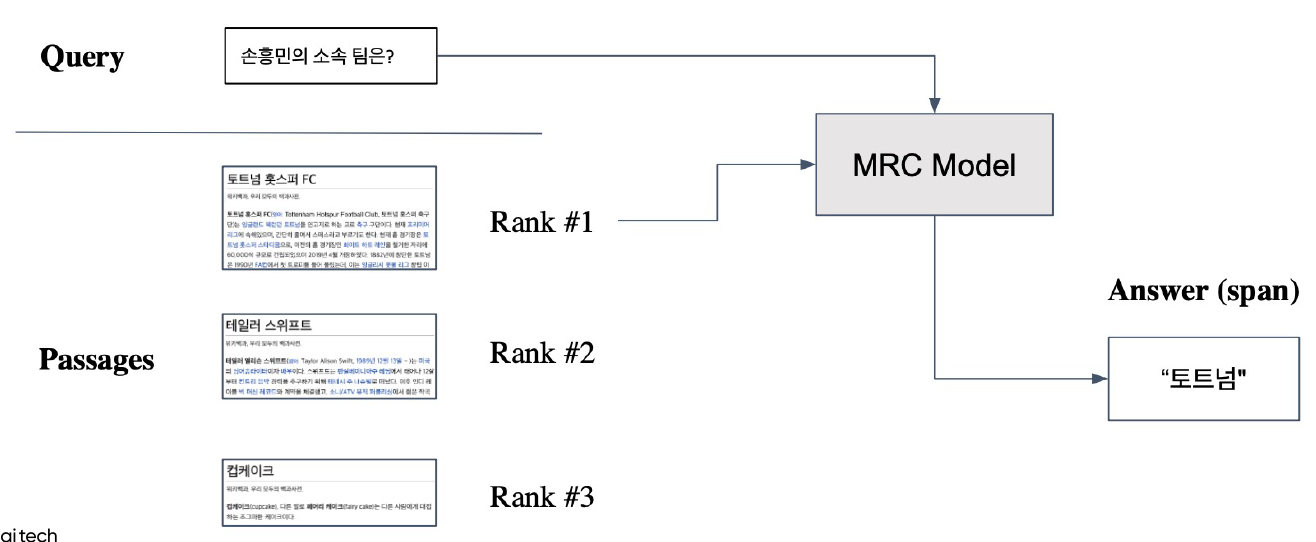
선택된 Passage와 query를 MRC model에 넣고 answer를 얻는다.
Improving Dense Encoder
- 학습 방법 개선
- e.g., DPR
- Encoder model 개선
- BERT보다 더 좋은 모델
- 데이터 개선
- 더 많은 데이터
- 더 좋은 전처리
Leave a comment