
GPT 언어 모델
- BERT: embedding 모델
- Transformer encoder 사용
- GPT: 생성 모델
- Transformer decoder 사용
GPT 개요
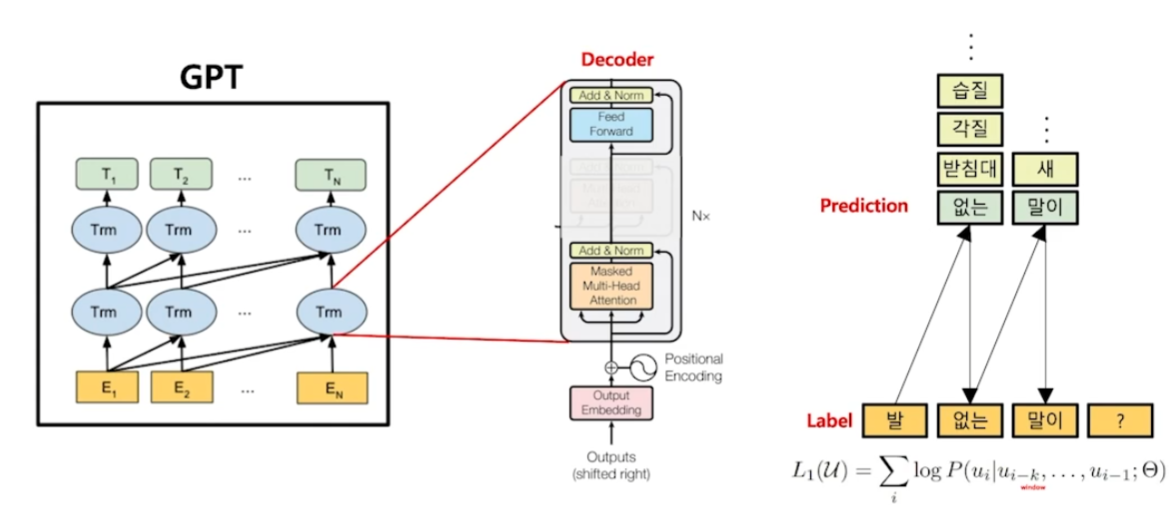
일반적으로 배웠던 Language model의 언어 생성 과정과 동일하다. 순차적으로 다음에 올 가장 적절한 단어들을 확률적으로 예측한다.
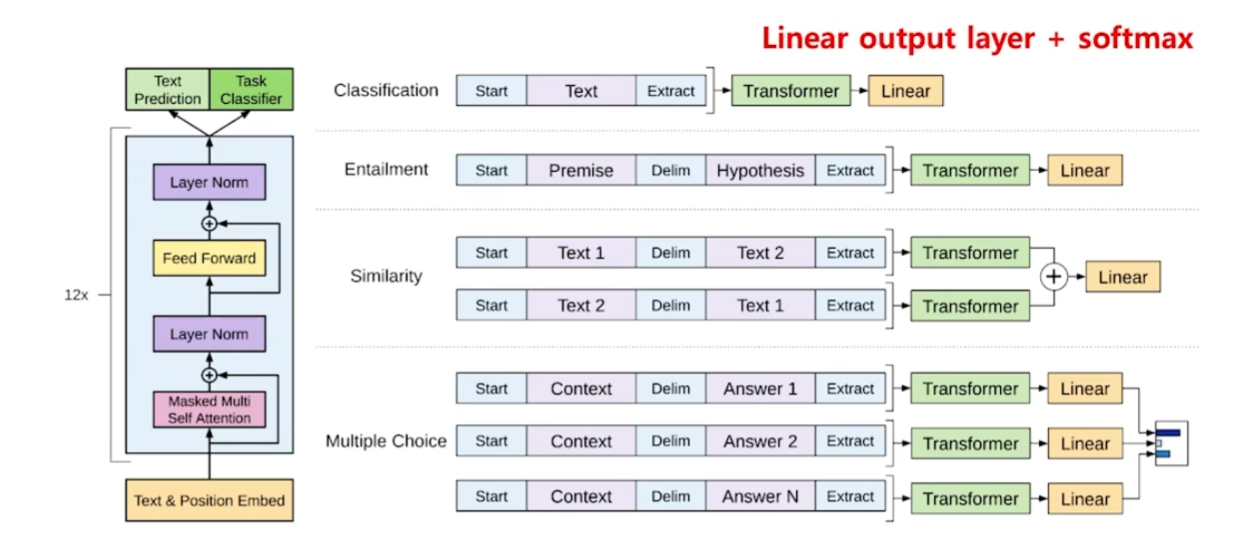
GPT-1은 마치 BERT처럼 모델의 뒷단에 원하는 classifer를 붙여서 특정 task에 적합하도록 fine-tuning할 수 있도록 구성됐다. 시기상으로는 GPT-1이 BERT보다 앞선다.
GPT-1은
- 자연어 문장 분류에 매우 유용한 디코더다.
- 적은 양의 데이터로도 높은 분류 성능 달성.
- 다양한 자언어 task에서 바로 SOTA 달성.
- Pre-train 언어 모델의 지평을 열면서 BERT 발전의 밑거름이 됐다.
- 지도 학습이 필요해 많은 labeld data가 필요.
- 특정 task를 위해 fine-tuning된 모델은 다른 task에서 사용 불가능.
GPT 연구진의 새로운 가설
언언의 특성 상, 지도학습의 목적 함수는 비지도 학습의 목적 함수와 같다. 즉, fine-tuning이 필요없다.
왜냐하면 labeld data의 label도 언어이기 때문이다.
다시 말하면, 굉장히 거대한 데이터 셋을 학습한 language model은 모든 자연어 task를 수행 가능하다는 것이다.
zero-shot, one-shot, few-shot
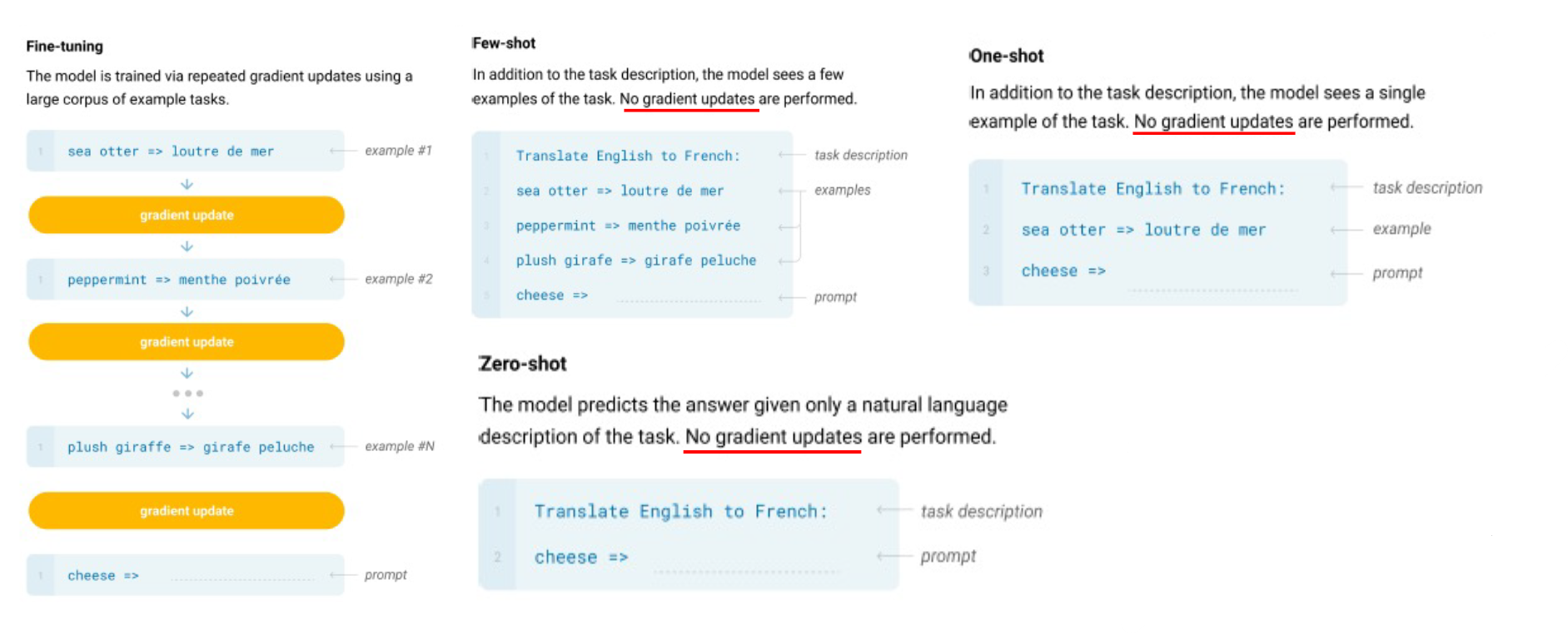
fine-tuning으로 하나의 task만을 위한 모델을 만드는 것은 불필요하다고 판단. 마치 인간이 새로운 task 학습을 위해 많은 데이터가 필요하지 않다는 것과 같은 이치로 language model에 접근해서 zero, one, few-shot으로 inference하는 방법론이 제시됨.
즉, 특정 task를 위해 gradient update를 하지 않고 task를 수행하는 것이다. 이러한 방법을 적용하기 위해 거대 데이터셋을 학습하는 모델을 개발했는데 이것이 GPT-2이다.
GPT-2
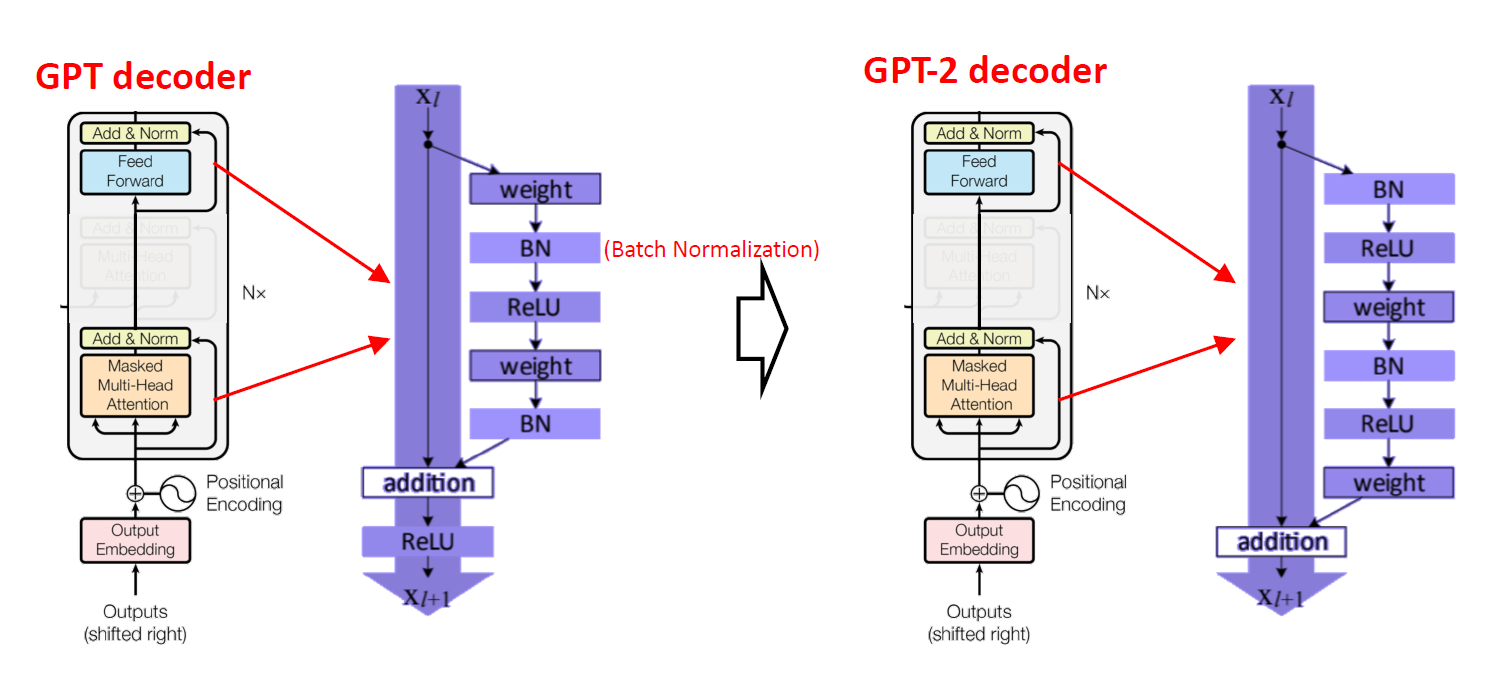 GPT-1에 비해서 약간의 decoder 구조 변경이 있다.
GPT-1에 비해서 약간의 decoder 구조 변경이 있다.
또한 train data는 11GB에서 40GB로 늘었다.

- MRC, summarization, translation 등의 자연어 task에서는 일반적인 신경망 모델 수준의 성능이었다.
- 다음 단어 예측에서는 SOTA
- zero, one, few-shot learning의 새 지평을 열었다.
GPT-3

- train data는 45TB에서 정제된 570GB를 사용
- Parameters는 1,500M에서 175,000M으로 증가.
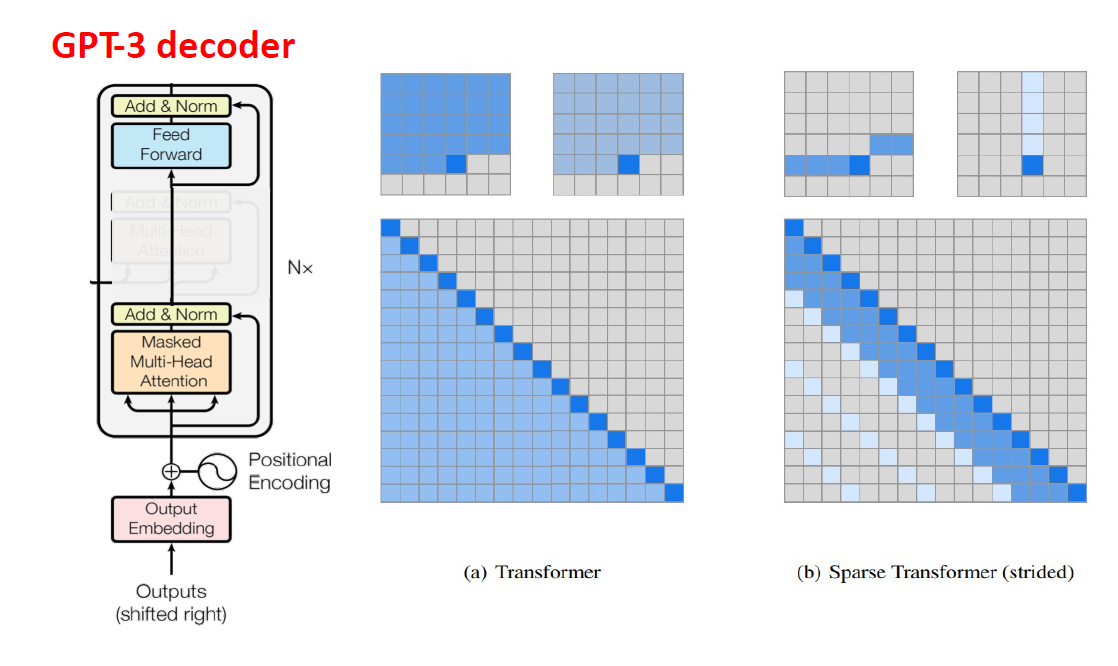
- Initialization 수정
- Sparse Transformer 사용
Task of GPT-3
- 기사 쓰기
- GPT-3가 작성한 기사들 중 52%는 실험자들이 인간이 작성한 기사 같다고 평가.
- 덧셈 연산
- 2 ~ 3자리수 숫자들의 덧셈 연산은 거의 정확하게 수행
- QA에서도 기존 모델보다 더 좋은 성능을 기록하기도 함.
- 데이터 파싱
- 특정 문서에서 알아서 데이터를 파싱해 표를 그려준다.
Restriction
GPT도 NSP(Next senetence prediction)를 통해 Pre-train된 모델이다.
- Weight update가 없다.
- 새로운 지식 학습 불가
- 모델 사이즈만 키우는 것이 만능인가?
- 아무도 모르지만 아마도 아닐 것.
- 멀티 모달 정보 활용 불가
Leave a comment