
Generation-based MRC
Generation-based MRC
context와 question을 보고 답변을 생성하는 task. Extraction-based MRC가 context의 token별로 정답 확률을 추출했다면, Genration-based는 이름처럼 Generation task다.
즉, Extraction-based MRC는 Generation-based MRC task로 변환이 가능하지만 역은 불가능하다.
평가 방법
Extraciton-based처럼 EM, F1 score를 쓸 수도 있지만 BLEU, ROUGE를 쓰는 것이 일반적이다.
Overview
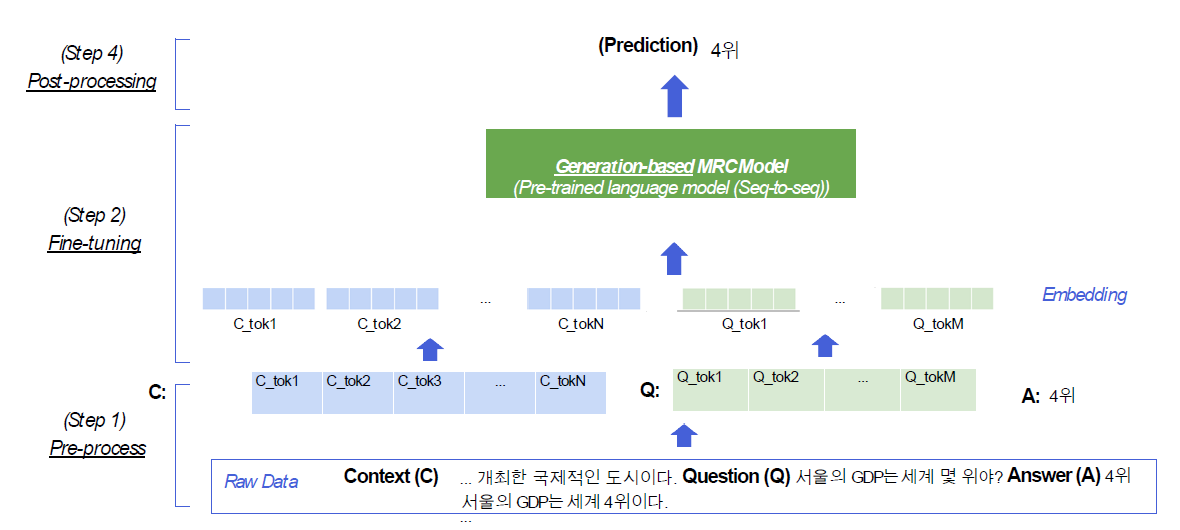 Extraction-based와 다르게 Generation-based는 모델이 정답을 즉시 생성한다. 일종의 Seq2Seq이다. BERT같은 경우 Encoder만 있기 때문에 Seq2Seq처럼 활용이 안된다.
Extraction-based와 다르게 Generation-based는 모델이 정답을 즉시 생성한다. 일종의 Seq2Seq이다. BERT같은 경우 Encoder만 있기 때문에 Seq2Seq처럼 활용이 안된다.
Extraction-based와의 차이
- Extraction-based
- PLM(Pre-trained Language Model) + Classifier
- Context 내의 답의 위치를 찾기 위해 loss 계산
- 모델의 출력을 answer로 변환하는 과정 필요
- Generation-based
- Seq2Seq PLM
- Free-form text 생성
Pre-processing
정답의 위치를 특정할 필요가 없어서 Extraction에 비해서 간단하다. Question, answering을 있는 그대로 주기만 하면 된다.
Toeknization
- WordPiece Tokenizer
Special token
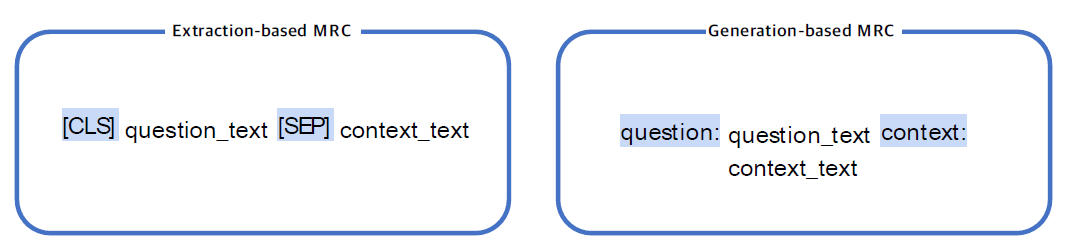
일반적인 LM과 같이 CLS, SEP, PAD 등이 사용될 수 있지만 모델마다 우측처럼 question, context로 문장을 구분하기도 한다. 모델마다 다르니 사용하고자 하는 모델이 요구하는 형식을 살펴보자.
Attention mask Extraction-based와 동일하게 일반적인 LM처럼 처리
Token type IDs BERT와 달리 BART는 sequence에 대한 구분이 없어서 token type IDs가 없다.
출력 표현 처리
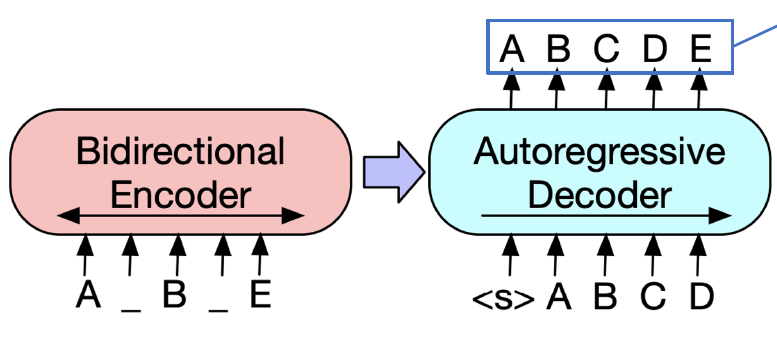
익히 알고 있는 Seq2Seq이기 때문에 Decoder의 출력 form에 대해서는 별도의 처리가 필요하지 않다.
Model
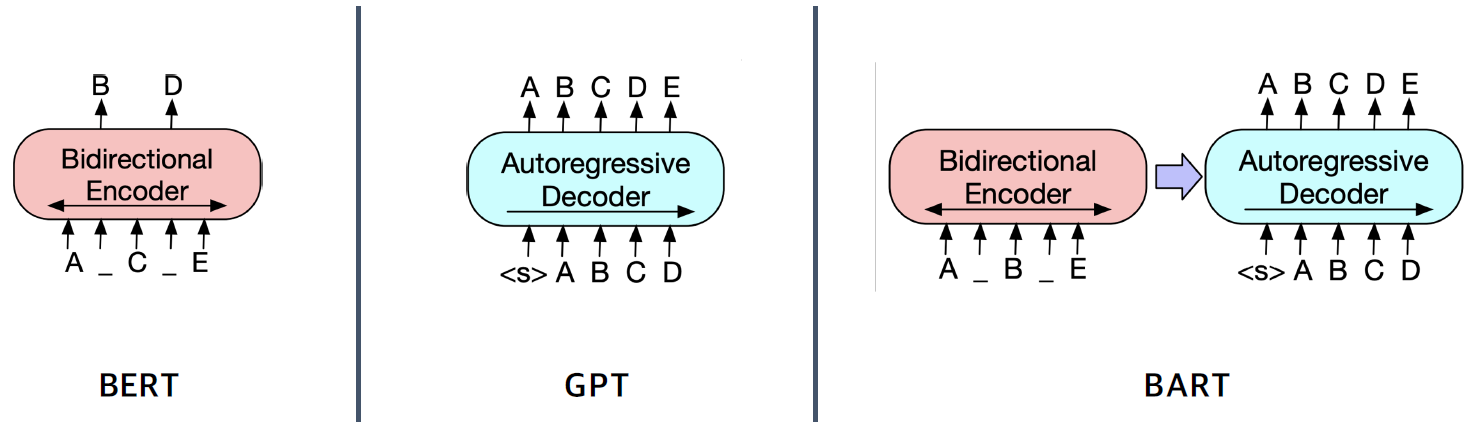 MRC에서는 Seq2Seq가 필요하기 때문에 BERT, GPT처럼 Encoder, Decoder만이 존재하는 모델이 아니라 Encoder, Decoder를 모두 가지고 있는 모델이 필요하다.
MRC에서는 Seq2Seq가 필요하기 때문에 BERT, GPT처럼 Encoder, Decoder만이 존재하는 모델이 아니라 Encoder, Decoder를 모두 가지고 있는 모델이 필요하다.
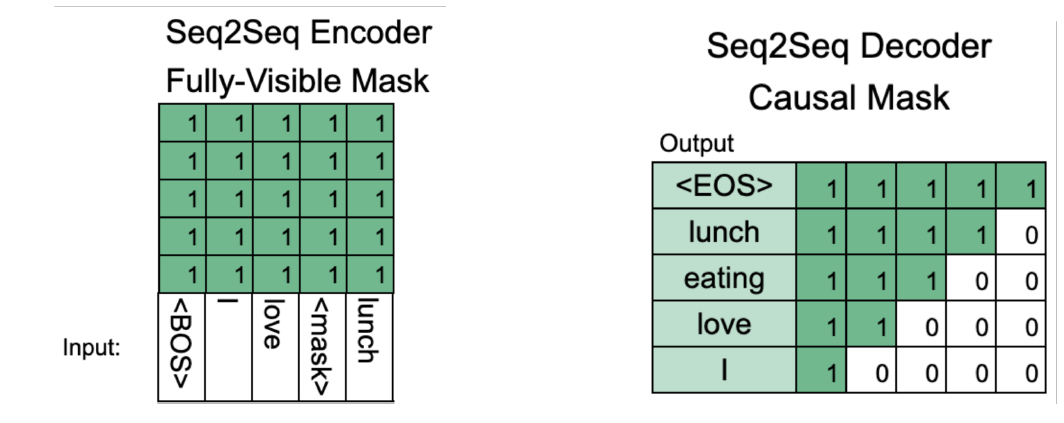
BART는 denoising autoencoder라고 한다. BERT처럼 masking이 된 문장을 input으로 하고 GPT처럼 문장을 생성한다. 이것이 마치 노이즈가 발생된 문장에 대한 autoencoder 형태와 같다고 해서 붙여진 것 같다.
BART
- Encoder: BERT처럼 Bi-directional
- Decoder: GPT처럼 uni-directional(autoregressive)
Pre-training BART
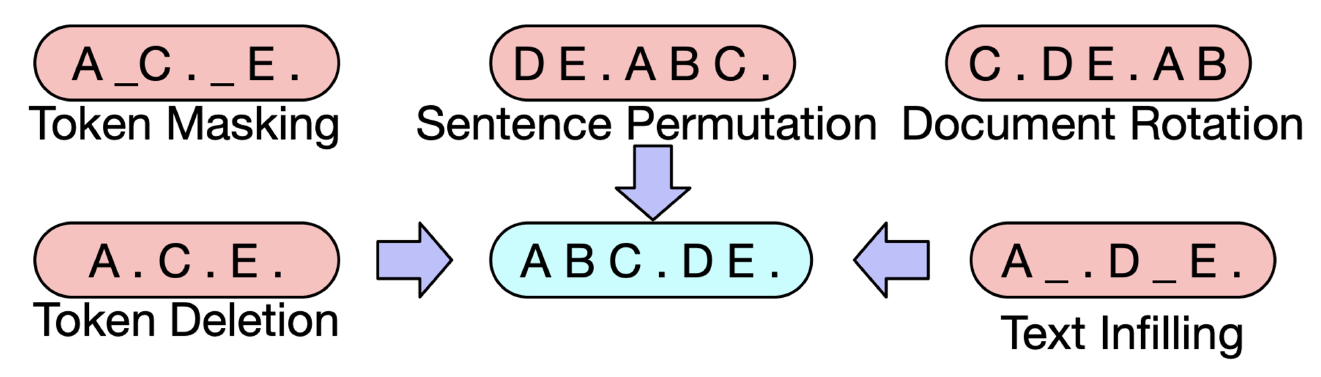
BART는 문장에 masking을 하고 원래 문장을 복구하는 모델이다. 즉, 이를 Generation에 사용하는 것이다.
Post-processing
Decoder에서는 여러 방법론을 선택할 수 있다.
- Greedy search
- Exhaustive search: 모든 가능성을 보는 것
- Beam search: Exhaustive를 하되 top-k만 본다.
Leave a comment