
Passage Retrieval
Passage Retrieval
query에 맞는 문서(Passage)를 검색(Retrieval)하는 것.
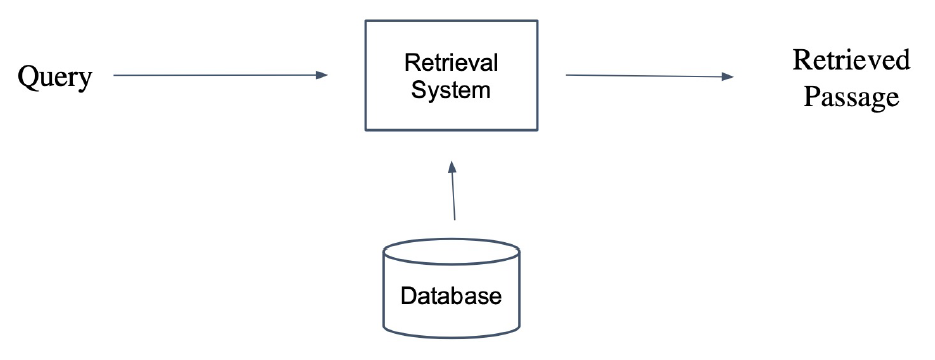
Database
- 실제로는 DBMS 활용할 수도 있다.
- 여기서는 Wiki data
Passage Retrieval with MRC
Open-domain Question Answering: 대규모 문서에서 질문에 대한 답 찾기
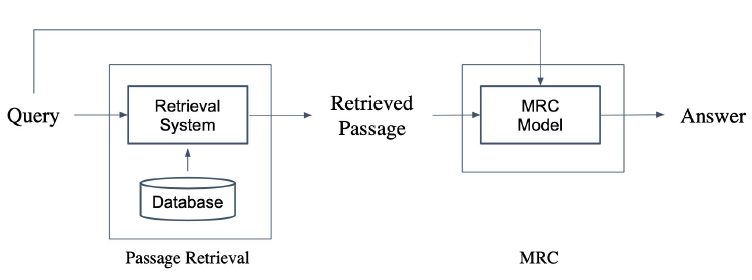
Passage Retrieval과 MRC를 결합하면 Open-domain Question Answering이 된다.
- Passage Retrieval
- 답이 있으리라 예상되는 context를 MRC 모델에게 준다.
- MRC
- 주어진 context를 통해 답 도출
Overview
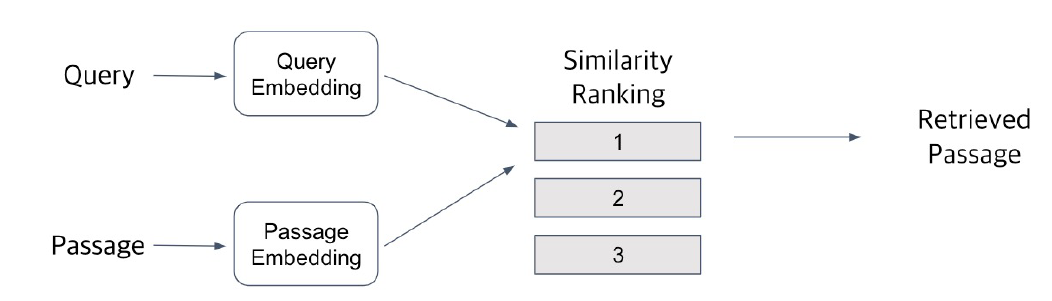 Passage Retrieval은 Embedding space를 기반으로 검색한다.
Passage Retrieval은 Embedding space를 기반으로 검색한다.
- Query, Passage를 Embedding Space에 Embedding한다.
- Passage는 미리 한꺼번에 Embedding해서 효율적으로 사용
- Query, Passage Embedding 사이의 similarity score 계산
- vector 사이의 거리 계산, 거리가 짧을수록 유사
- inner product 계산, 값이 클수록 유사
- Query에 대해서 Passage들의 similarity ranking을 매겨서 출력
Passage Embedding
마치 Word Embedding을 하듯이 Passage를 vector화 하기 위해 Embedding한다.
 우리가 일반적으로 아는 Embedding space처럼 vector간 inner prodcut, 거리 계산을 통해 similarity를 계산한다.
우리가 일반적으로 아는 Embedding space처럼 vector간 inner prodcut, 거리 계산을 통해 similarity를 계산한다.
Sparse Embedding
Sparse: dense의 반대. 0이 아닌 숫자가 매우 적게 존재함을 의미.
대표적으로 BoW(Bag Of Words)가 있다. 단어들이 하나의 차원을 구성하게 되면서 문서를 Embedding할 때 Vocab의 수만큼 차원이 존재해야한다. 즉 필연적으로 대부분은 0으로 매꾸지고 매우 적은 숫자들만이 0이 아니게 될 것이다.
BoW에서 n-gram의 n을 늘릴수록 구성가능한 경우의 수는 기하 급수적으로 늘어난다. 따라서 bigram(2-gram)까지만 활용하고 간혹 trigram까지 활용한다.
** Term value **
- Term(단어)이 document에 등장하는지에 대한 여부만 판단(binary)
- Term이 몇 번 등장하는지 판단(term ferquency).
- e.g., TF-IDF
Sparse Embedding의 특징
- Dimension of embedding vector = number of terms
- n-gram의 n이 커질수록 커진다.
- Term overlap을 정확하게 파악해야 할 때 유용
- e.g., 검색 시 term이 문서에 포함됐는지를 판단
- 의미(semantic)가 비슷하지만 다른 단어인 경우 비교 불가
- 전혀 불가능하다!
TF-IDF
Term frequency - Inverse Document Frequency
- TF(Term frequency): 단어의 등장 빈도
- raw count / num words를 구하고 normalization을 한다.
- log normalization을 하기도 한다.
- IDF(Inverse Document frequency): 단어가 제공하는 정보의 양
- 자주 등장하는 단어들: 제공하는 정보량이 적다고 판단
- 자주 등장하지 않는 단어들: 제공하는 정보량이 많다고 판단
IDF
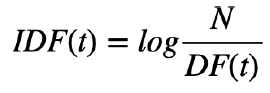 \(DF(t)\): Term t가 등장하는 문서의 수
\(DF(t)\): Term t가 등장하는 문서의 수
- TF와 다르게 term에만 의존한다.
- Term t가 등장하는 문서가 적을수록 IDF(t)의 값이 커진다.
TF-IDF \(TF-IDF = TF(t,d) \times IDF(t)\)
- 관사들은 Low TF-IDF일 것이다.
- TF가 높을 수 있지만, IDF가 0에 수렴하기 때문이다.
- 자주 등장하지 않는 고유 명사들은 High TF-IDF일 것이다.
- TF가 낮더라도 IDF가 많이 커지기 때문이다.
TF-IDF 계산
각각의 term에 대해서 한번씩 구할 수도 있지만 표끼리 곱하는 형식으로 구할 수 있다.

row는 하나의 문서를 나타낸다. column은 vocab이다. 예시에서는 하나의 문서에는 하나의 vocab 요소만 들어가서 모든 값이 0 혹은 1이다. 즉, 표의 값들이 바로 TF 값들이 된다.

IDF 값을 term에 대해서 구했다. term에만 의존되기 때문에 문서에 무관하게 같은 값을 가진다.
TF-IDF는 TF와 IDF 값을 곱하면 되므로 위의 두 표를 element-wise하게 곱하는 것만으로도 전체 TF-IDF를 구할 수 있다.

TF-IDF 활용
Passage retrieval에서 query와 passage 사이의 similarity를 얻는데 사용할 수 있다.
- query를 toeknization
- vocab에 없는 token들은 제외
- query를 document로 간주하고 TF-IDF 계산
- 미리 구해둔 passage들의 TF-IDF와 유사도 점수 계산
- 가장 높은 점수를 가지는 passage 채택
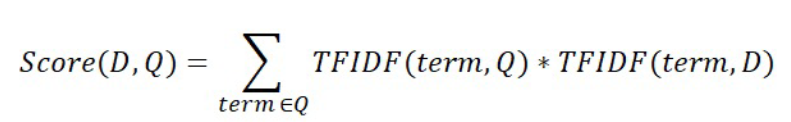
BM25
TF-IDF에 기반. 문서의 길이까지 고려하여 점수를 매긴다.
- TF 값에 한계 지정.
- 평균적인 문서의 길이보다 더 작은 문서에서 term이 매칭된 경우, 더 작은 문서에 가중치 부여
- 실제 검색엔진, 추천 시트템 등에서 아직까지 많이 사용되는 알고리즘

Leave a comment