
Grad Cache
추가 예정..
Grad Cache
Overview
In-batch negative 방식의 contrastive learning에서 마치 gradient accumulation처럼 large batch를 사용하게 해주는 방식이다.
일반적인 학습 방법의 경우, batch-wise하게 loss 계산을 하지 않기 때문에 loss update를 한꺼번에 모아서 하는 것에 문제가 없다. 하지만, DRP, MRC model과 같이 contrastive leraning을 시도할 때 in-batch negative를 사용할 경우, batch-wise하게 loss가 계산되기 때문에 batch 내 data들간에 종속성이 발생한다. 따라서 contrastive learning에서는 gradient accumulation이 사용 불가능하다.
Grad Cache에서는 grad accumulation과 유사한 방법을 contrastive learning에서 구현해, single gpu로도 많은 batch size를 확보할 수 있도록 해준다.
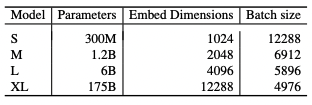
Text and Code Embeddings by Contrastive Pre-Training에서 batch size를 12288까지 늘린다. 하드웨어적으로 불가능에 가까운 영역이기 때문에 contrastive learning에서 큰 batch size를 확보하기 위해 Grad Cache를 사용한다.
Method
Reference
- Arxiv: Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup
- https://seopbo.github.io/gradCache/
- https://github.com/luyug/GradCache
Leave a comment