
Condenser, coCondenser
스터디에서 진행했던 논문 리뷰 발표 정리.
https://github.com/luyug/Condenser
Condensor
Abstract
PLM은 text comparison과 retrieval에서 좋은 성능을 보여줬다. 하지만 dense encoder를 학습시키기 위해서는 많은 데이터와 복잡한 기술이 요구된다. 이 논문은 표준적인 LM의 내부 구조가 dense encoder로 사용되기에 충분하지 않은 이유를 밝힌다. 또한 Condenser가 text retrieval와 이와 유사한 task에서 표준적인 LM보다 더 좋은 성능을 보임을 보여준다.
Issues with Transformers Encoder
Transformers에서 CLS token을 포함한 모든 token들은 한번의 attention으로 sequence 상의 다른 token들에 대한 정보를 받는다. CLS token에 대한 분석 논문에서는 다음과 같이 CLS token에 대해 분석한다.
- 대부부의 middle layers에서 CLS token은 다른 text token들과 유사한 attention pattern을 가지게 되고, 다른 token들에 의해서 attention되지 않는다.
- last layer에서 CLS는 NSP task를 위해 uniqe한 broad attention을 가진다.
이러한 분석들을 종합하면 CLS token은 많은 middle layers에서 활성화되지 않다가, 마지막 attention round에서만 활성화된다고 생각할 수 있다. 논문에서 정의하고 싶은 효과적인 bi-encoder는 all layers를 통해 서로 다른 수준의 정보를 집계할 수 있어야 한다고 말한다. 이러한 관점에서 표준적인 PLM은 fine-tuning을 위한 준비가 되지 않았다고 주장하는 것이 논문의 요지이다.
Method
Pre-training
논문은 아래와 같은 model design을 통해 이를 해결하고자 한다.
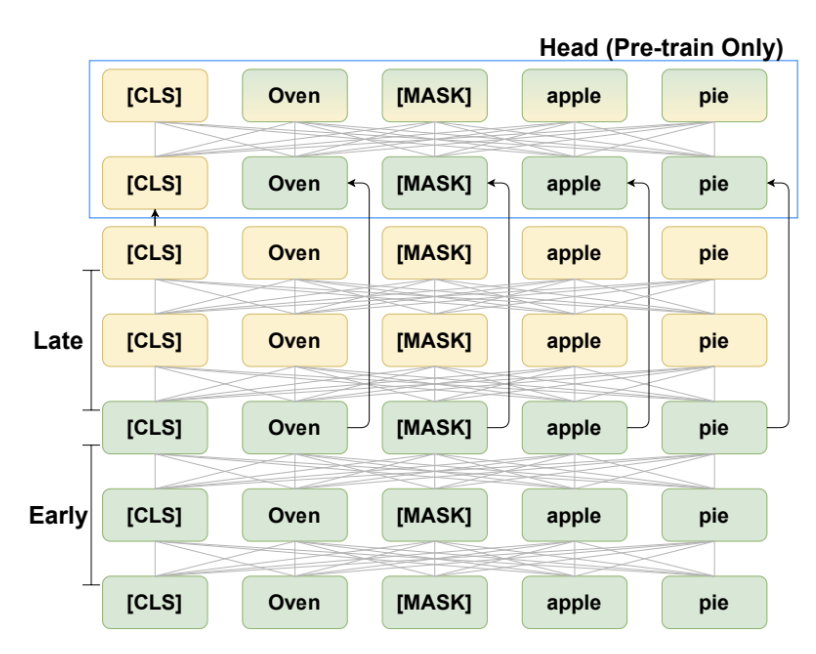
하나의 attention만으로 pre-trainig하지 않고, early encoder, late encoder, condenser header를 통해 pre-training을 하고자 주장한다. 이를 early encoder, late encoder를 수식으로 표현하면 아래와 같다.
\[[h^{0}_{cls};h^{0}] = Embed([CLS;x])\] \[[h^{early}_{cls};h^{early}] = Encoder_{early}([h^{0}_{cls};h^{0}])\] \[[h^{late}_{cls};h^{late}] = Encoder_{late}([h^{early}_{cls};h^{early}])\]early encoder의 hidden state가 skip connection으로 condenser head에 들어간다. (논문에서는 short circuit이라고 표현했다) late encoder의 CLS가 condenser head에 투입되면서 late-early representation이 condenser head가 들어가도록 유도한다.
MLM Loss는 아래와 같이 구한다.
\[\mathcal{L}_\text{mlm} = \sum_{i \in \text{masked}} \text{CrossEntropy}(W h^{cd}_i, x_i)\]이러한 구조에서 late encoder이 token representation을 refine(정비?, 정제?)할 순 있지만 오직 $h^{late}_{cls}$를 통해서만 새로운 정보를 통과시킨다. 따라서 late encoder는 새롭게 생성되는 정보들을 CLS representation에 집계하려고 노력할 것이고, heads는 late CLS에 의존해서 prediction을 하게 된다.
early layer의 hidden state를 skip connecting함으로써 encoding 결과의 local information과 input text의 문법적인 구조를 제거했다. 논문에서는 이를 통해 CLS가 input text의 global meaning에 집중하도록 했다고 주장한다.
Fine-tuning
Condenser의 fine-tuning에서 head는 drop된다. Fine-tuning을 통해 $CLS\ h^{late}_{cls}$를 학습하고 backprogate하며 backbone의 graident를 update한다. head가 pre-training의 guide만을 수행하면서 Condenser는 encoder backbone의 크기를 줄일 수 있고 효율적으로 변한다. 실제로, Condenser는 경량화된 BERT의 대체품이 될 수 있다.
Weight Initialization
Condenser의 head는 random하게 초기화하고 early, late encdoer는 기존 PLM의 weight를 사용했다. 개인적으로 이러면 연구가 너무 쉬운게 아닌가?. .싶긴했다.
Head에 대해서 gradient backpropgation을 수행할 때 backbone weight가 이를 방해하는 것을 막아야 한다. 따라서 late output에 대한 MLM을 문맥적인 제약사항으로 아래와 같이 사용하여 Loss에 추가했다.
\[\mathcal{L}_\text{mlm}^c = \sum_{i \in \text{masked}} \text{CrossEntropy}(W h^{late}_i, x_i)\] \[\mathcal{L} = \mathcal{L}_\text{mlm} + \mathcal{L}_\text{mlm}^c\]Result
Sentence Similarity

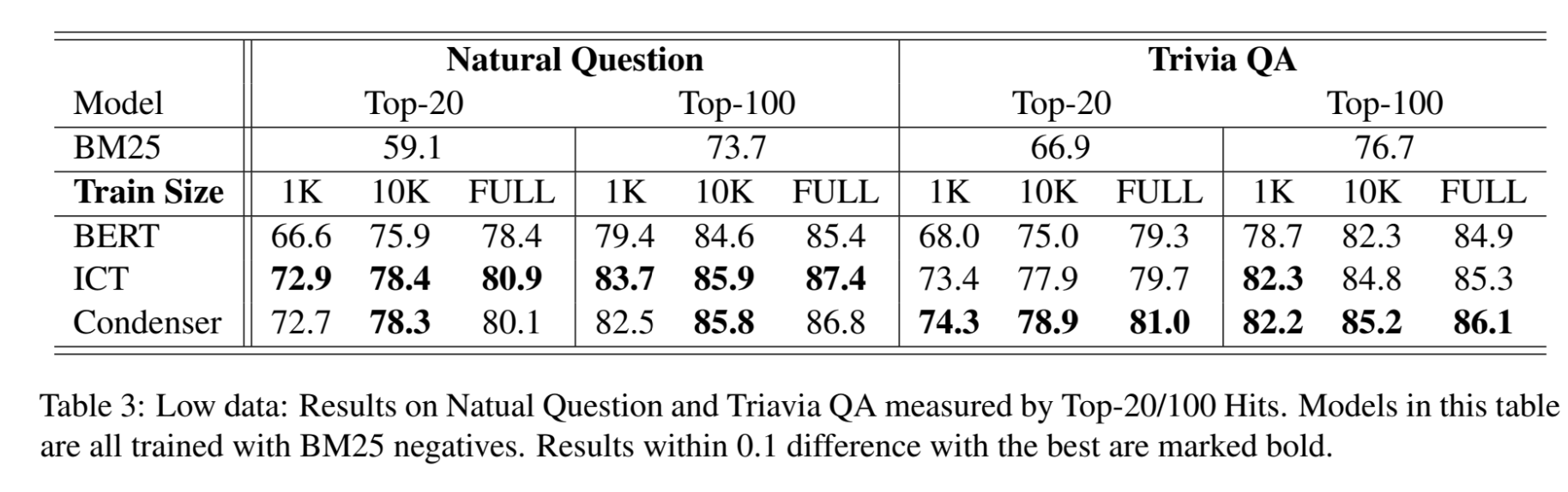
Retrieval for Open QA
Open-domain에서의 retrieval 성능을 말하는 듯 하다.
Retrieval for Web Search
Open-domain이되 Web Search에 대한 지표.

coCondenser
이 논문에서는 기존의 dense retrieval가 가지는 두 가지 문제점에 대해서 밝힌다.
- 학습 데이터의 노이즈
- large batch size에 대한 요구
논문은 Condenser를 pre-training architecture로 사용했다. 또한 passage embedding space를 학습하기 위해서 unsupervised corpus-level contrastive loss로 학습하는 coCondenser를 제안한다.
coCondenser는 larget batch trainig뿐만 아니라 augmentation, synthesis, filtering과 같은 heavy data engineering의 필요성을 제거해준다.
Leave a comment