
Med-BERT
Primary conrtributions
논문에서 직접 제시한 contriubution들은 다음과 같다.
- 실제 세계의 modeling task에서 structured EHR로 학습한 BERT-style model이 얼마나 의미있는지 PoC한 첫번째 연구
- EHR data에서 일반적이고 contextual semantics를 capture 할 수 있는 domain-specific한 cross-visit pretrainig task를 디자인
- Phenotyped cohorts에서 multiped clinical task를 수행하는 SOTA methods보다 더 좋은 성능을 보여준 첫번째 demonstration
- Trainig dataset(Cerner)이 아닌 dataset(Truven)을 사용하여 EHR BERT 모델의 일반화
- Med-BERT의 성능 향상이 모든 sample size에서 관촬됨. Training data가 제한된 상황에서도 Pretraning model이 잘 작동.
- EHR의 dependency semantic 시각화 툴 제공.
- Pretrained model, code 공개.
Abstract
Structured EHR(Electronic Health Record)를 transfer learning으로 모델링하고자 하는 기존 연구들로 BEHRT와 G-BERT가 있었다.
BEHRT는 방문 기록에 대한 medical codes에 대한 prediction을 통해 pretrain했다. 이는 AUC와 같이 non-standard한 지표를 사용했기에 기존 연구와 비교하기 어려웠다.
G-BERT는 clinical code를 통해 GNN과 BERT embedding을 학습했다. 이 모델은 MLM의 pretrainig task를 기존 clinical code와 존재하지 않는 clinical code 간의 차이를 극대화하고 서로 다른 clinical code를 예측할 수 있는 domain specific task로 변경했다. 하지만 G-BERT의 input data는 single-visit sample인데 이는 EHR의 long-term contextual information을 식별하기에 부족했다.
앞선 이슈들과 disease predction에 특화된 모델을 예측할 수 있도록 논문은 Med-BERT를 디자인했다고 한다. 기존의 BERT는 free text로부터 학습했다면 Med-BERT는 IDC(Internatinal Classification of Disease) codes를 사용한 구조화된 진단 데이터를 사용하여 학습했다.
Compare with relevant study
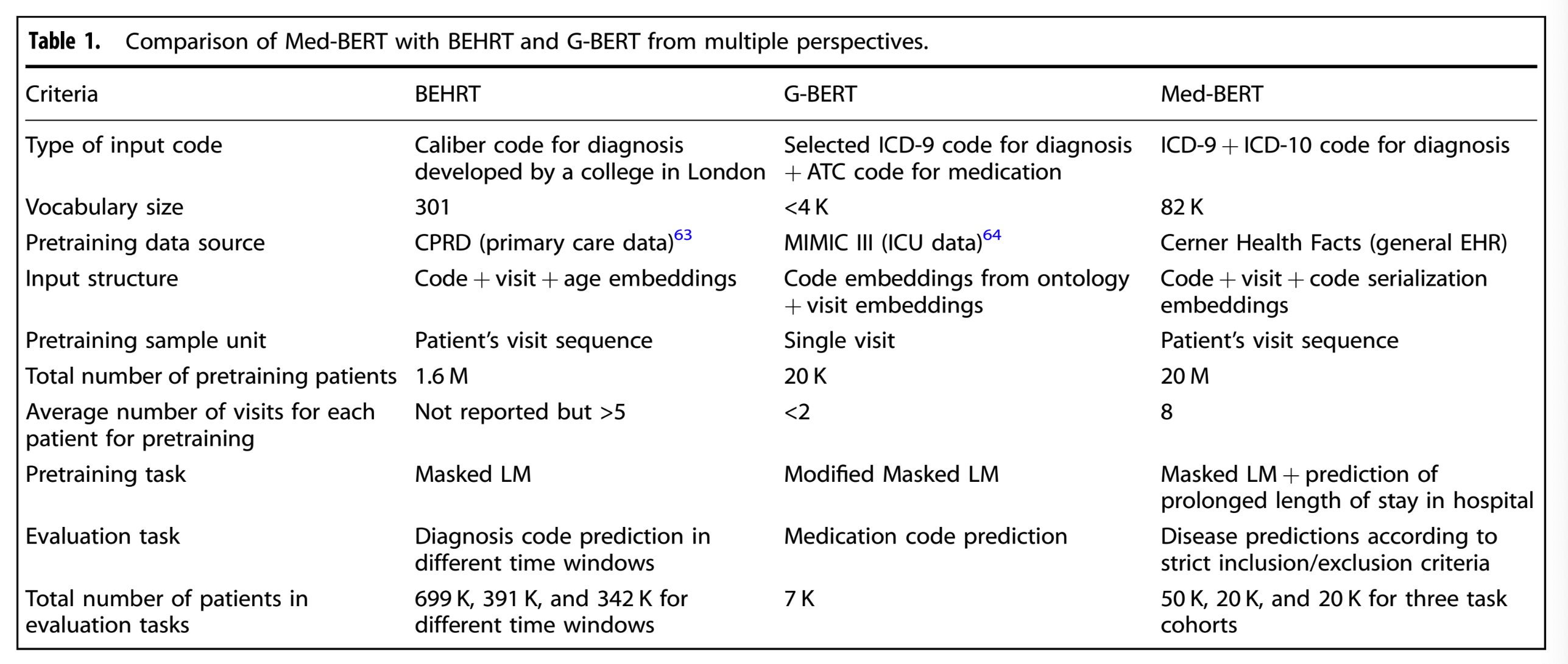
Med-BERT는 BEHRT, G-BERT보다 큰 vocab size를 가지고 더 큰 pretraining cohort를 가지고 있다. 논문은 larger cohort size와 longer visit sequence로 pretraining 했기 때문에 contextual semantic을 이해하는데 더 도움이 될 것이라고 주장한다.
또한 ICD-9, ICD-10과 같은 large/publicly accesiible vocabulary와 여러 기관의 데이터로 pretrainig했기 때문에 각기 다른 기관과 clinical scenario에도 적합할 것이라고 주장한다.
BEHRT, G-BERT와 유사하게 Med-BERT는 clinical code에는 code embedding을, 서로 다른 visit에 대해서는 visit embedding을, code간의 상호관계를 식별하기 위해서는 transformer를 사용했다. BEHRT, G-BERT는 visit에 code ordering을 사용하지 않았지만, Med-BERT는 serialization embedding을 통해 code의 상대적인 순서를 나타낸다.
논문에서는 Prolonged legth of stay in hospital(Prolonged LOS, 장기 입원 기간)을 에측하는 domain-specific한 pretraining task를 디자인했다. 이는 질병 진행 상태에 따라 환자의 건강 정보에 대한 심각성을 평가하기 위한 모델링잉 필요하고 human annotation을 요구하지 않는 유명한 clinical probelm이라고 한다. 이러한 task를 학습하는 것은 모델이 clinical하고 contextualized features를 더 잘 학습하도록 도움이 될 것이다.
Fine-tuning
Pretrained Med-BERT의 유용성은 두 개의 다른 EHR datasets의 3개의 patient cohorts로부터 다음 두 가지 prediction task에 대해 fine-tuning하여 평가한다.
- Heart failure among patients with diabets (DHF, 당뇨병과 관련된 심부전)
- Oneset of pancreatic cancer(췌장암 발생)
해당 task들은 pretraing의 prediction task인 MLM과 Prolonged LOS와 다르기 때문에 모델이 얼마나 일반화되어 있는지 평가하기 좋을 것이라고 논문은 주장한다. 위 2개 task들이 fine-tuning taks로 선택된 이유는 다음과 같다.
- 특정 diagnosis codes보다 복잡한 정보를 내포하고 있다.
- 해당 task들은 시간대 제약, 진단 발생 시점, 약물, 연구실 실험 데이터와 같은 정보를 내포하는 diagnosis code를 넘어서 여러 정보를 통합하는 phenotyping algorithms를 기반으로 한다.
Fine-tuning은 다음과 같은 목적으로 진행했다.
- 3개의 SOTA model에 Med-BERT를 추가하여 성능 향상을 test
- Med-BERT와 pretrained non-contextualized embedding인 word2vec-style embedding의 비교
- 서로 다른 fine-tuning training size에 대한 Med-BERT의 disease prediction performance
Med-BERT architecture
Input data modality
Original BERT paper와 동일한 architecture(multi-level embedding, bidirectinal transformer)와 유사한 pretraining techniques(loss funcion on masking, classification pretraining task)을 사용했다. EHR과 text간의 semantic한 차이가 있기 때문에 BERT의 방법론을 structured EHR에 사용하는 것은 중요하다. ?
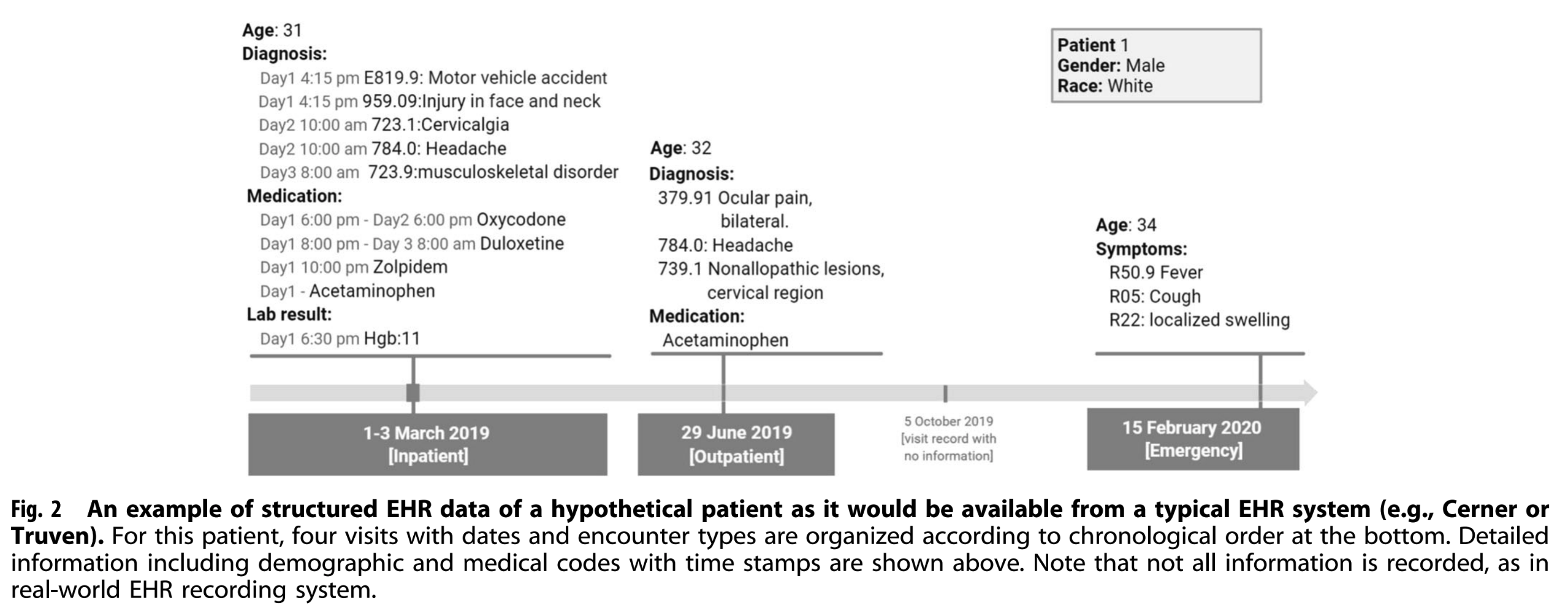
original BERT의 input data는 1 dimension이지만, structured EHR은 multilayer, multi-relation style의 데이터다. 따라서 structured EHR 데이터를 1 dimension으로 flatten하고 BERT에 맞게 encoding을 어떻게 할지가 중요하다.
Table3에서 이러한 차이점을 명시했다.
Model architecture
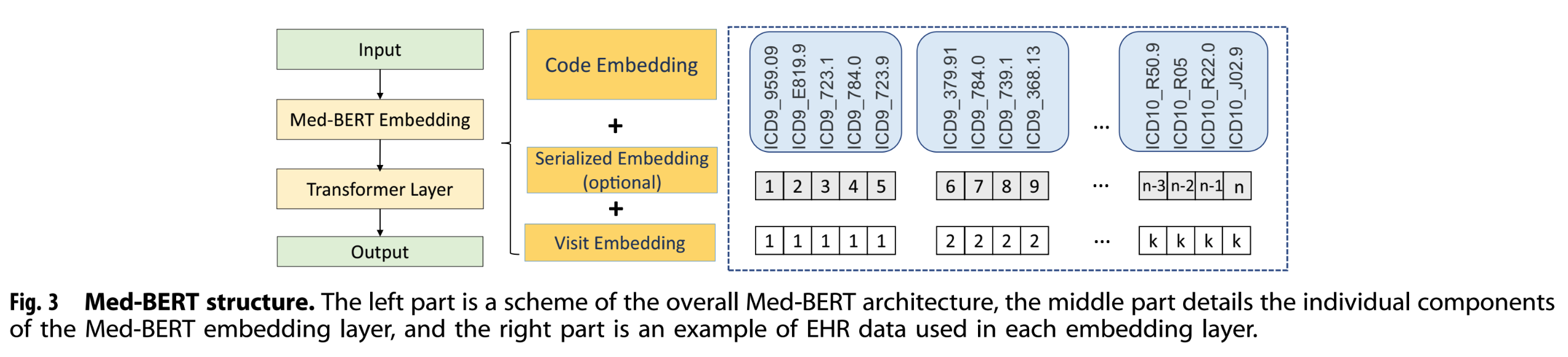
Med-BERT에는 3가지 형태의 input이 존재한다.
- code embedding
- Low-dimensional representations of each diagnosis code
- serialization embedding
- Relative order of each visit. 이 논문의 데이터에 대해서는 priority order, of each code in each visit를 의미.
- visit embedding
- sequecne에서 각각의 visit를 구분
BERT와 다르게 [CLS], [SEP]를 쓰지 않았다. [CLS]에 정보 요약을 하기에 sequence의 길이가 매우 길기 때문에, 별도의 feed-forward layer로 output token들의 내용을 압축한다. 또한 visit embedding만으로도 각각의 visit 정보들을 잘 분리할 수 있기 때문에 [SEP]가 불필요하다고 논문은 주장한다.
Pretraining Med-BERT
Original BERT paper의 recommended hyperparamter와 알고리즘으로 pretraining했다.
Masked LM
Orignial BERT paper의 masking 알고리즘을 사용했다. 임의의 code에 대해서 80%의 확률로 [MASK] 토큰으로 변환되고, 10%의 확률로 random code로 변환되고, 10%의 확률로 바뀌지 않는다.
Prediction of prolonged length of stay (Prolonged LOS) in hospital
Pretrained model의 generalizability를 위해 disease-specific하지 않고 pretrainig dataset과 유사한 clinical problem을 설정했다고 한다. 병원에서 일반적으로 사용되는 quality-of-care indicators(치료 품질 지표), mortality(사망률), earlyf readmission(입원), Prolonged LOS가 Pretrainig task 후보였다. 이 중, mortality와 early readmission은 99%를 초과하는 정확도를 보이며 비교적으로 매우 쉬운 task라고 판명됐다고 한다. 따라서 입원 날짜가 7일을 넘기는지 평가하는 task를 pretraining task로 정했다.
데이터 구조적으로 prolonged LOS는 Med-BERT의 bidirectional한 구조를 활용한다. 왜냐하면 과거 방문에서 기록된 환자의 건강 정보와 다음 방문에 대해서 LOS는 영향력을 가지기 때문이다. 반면, disease onest이나 mortality는 항상 환자 정보 sequence 중 마지막 방문에서 끝날 수 밖에 없기 때문에 one directional한 구조를 가진다.
Downstream prediction task by fine-tuning
Pretrainig model은 input data에 대해서 general purpose embedding을 출력할 뿐, prediction labael을 출력할 수 없다.
EHR predicitive model에서는 prediction head로 RNN을 사용했다.
Evaluation
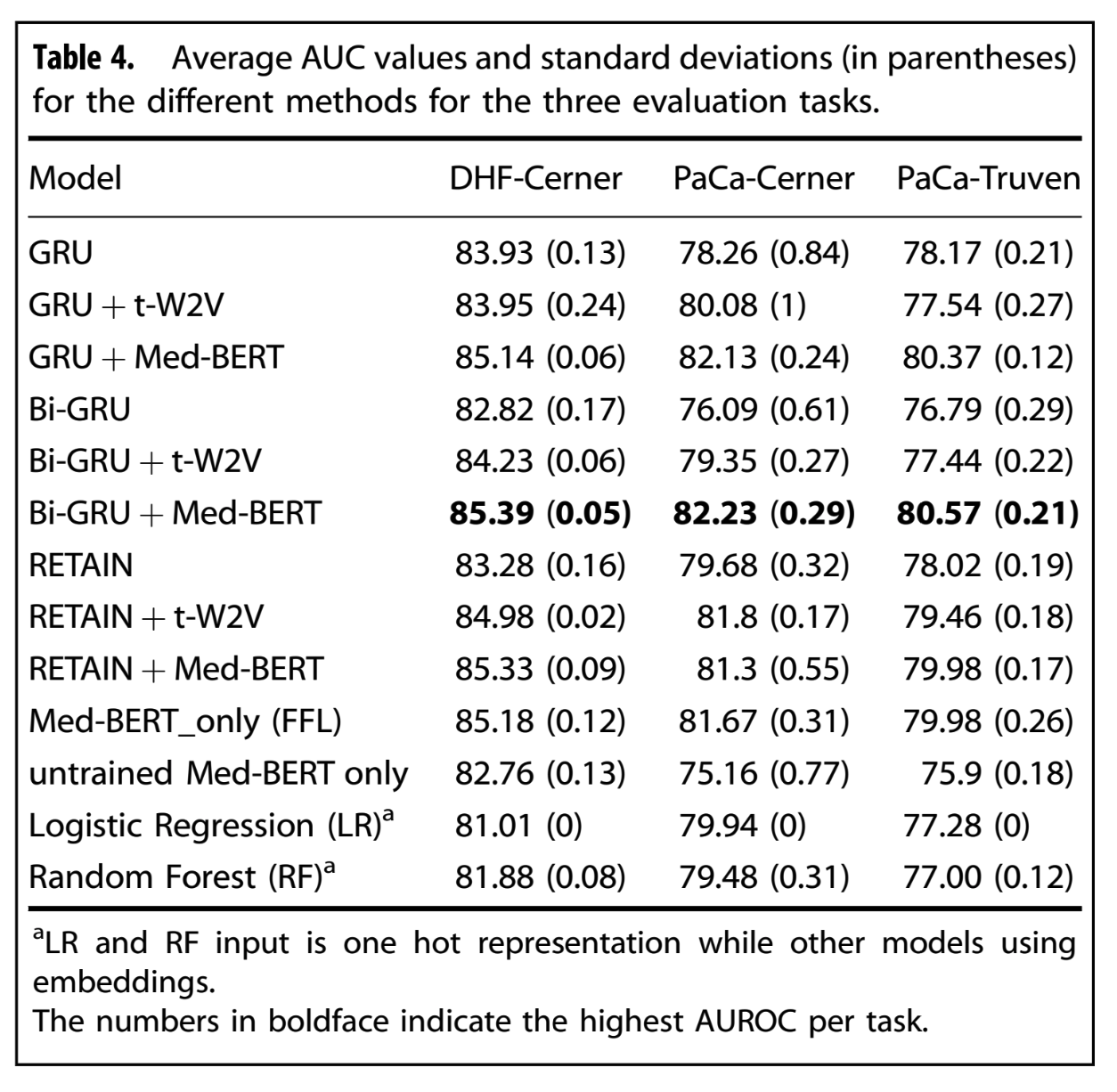
2개의 Database에서 가져온 3개의 cohort로부터 two disease prediction task를 수행하여 평가했다.
- two task: DHF, PaCa prediction
- 3 cohort: DHF-Cerner and PaCa-Cerner cohort for both task; Truven for only the pancreatic cancer prediction
BEHRT, G-BERT와 다르게 Med-BERT는 pretrainig task와 evalutation task가 보다 복잡하고 phenotyping from multiple perspectives가 요구된다. 따라서 논문에서는 논문의 방법론이 보다 현실적이고 generalizability를 확립하는데 도움이 된다고 주장한다.
비교에 사용된 method들은 다음과 같다.
- GRU, Bi-GRU
- RETAIN: a popular disease prediction model with double GRUs with attention model
- L2LR: L2-regulariezd logistic regression
- RF: random forest
Reference
- Med-BERT: https://www.nature.com/articles/s41746-021-00455-y
- Med-BERT Github: https://github.com/ZhiGroup/Med-BERT
- BEHRT: https://www.nature.com/articles/s41598-020-62922-y
- G-BERT: https://arxiv.org/abs/1906.00346
Leave a comment